Введение
Предобработка данных — это неотъемлемая часть процесса машинного обучения, которая включает в себя подготовку и очистку данных перед их использованием в моделях. Качество данных оказывает непосредственное влияние на точность и производительность моделей. Недостатки в данных, такие как пропуски, дубликаты и выбросы, могут привести к неправильным выводам и ухудшению результатов обучения.
Важность предобработки данных становится особенно актуальной в условиях больших объемов информации, с которыми сталкиваются современные системы машинного обучения. Эффективные методы предобработки позволяют не только улучшить качество входных данных, но и оптимизировать обучение моделей, что в конечном итоге приводит к более точным прогнозам и выводам. Таким образом, понимание основ предобработки данных и применение правильных методов является ключевым фактором для успешной реализации проектов в области машинного обучения.
Понимание данных
Понимание структуры и характеристик данных — это первый шаг на пути к их эффективной предобработке. Этот этап включает в себя анализ и визуализацию данных, что позволяет исследовать их распределение, выявлять аномалии и лучше понимать связи между признаками.
Для анализа данных часто используются библиотеки Python, такие как Pandas и Matplotlib.
При помощи Pandas можно удобно манипулировать данными, используя такие методы, как describe(), который предоставляет статистическую информацию о числовых столбцах, и info(), который позволяет получить общее представление о DataFrame. Визуализация данных с помощью Matplotlib и Seaborn помогает графически представить распределение данных, выявить потенциальные аномалии и выявить паттерны, которые могут быть полезны для дальнейшей предобработки.
Применение инструментов для визуализации данных, таких как гистограммы, диаграммы рассеяния и ящики с усами, позволяет лучше понять распределения и зависимости между переменными. Например, гистограммы могут показать распределение отдельных признаков, а диаграммы рассеяния помогут выявить взаимосвязи между двумя количественными переменными.
Очистка данных
Очистка данных — это важный этап предобработки, который включает в себя несколько ключевых процессов: обработку пропусков, удаление дубликатов и обработку выбросов. Каждый из этих процессов необходим для повышения качества данных и, как следствие, улучшения работы моделей машинного обучения.
Обработка пропусков
Пропуски в данных могут возникать по различным причинам: ошибки при сборе данных, некорректные записи или технические сбои. Обработка пропусков может выполняться различными методами:
1. Удаление строк/столбцов:
- Если в определенной строке или столбце слишком много пропусков, имеет смысл удалить их. Например, если в столбце содержится более 30% пропусков, его можно исключить из анализа, так как такой объем недостающих данных может сильно исказить результаты. Удаление строк с пропусками также может быть уместным, особенно если потеря информации не критична.
2. Импутация значений:
- Импутация — это процесс заполнения пропусков определенными значениями [1]. Существует несколько подходов:
- Среднее значение: наиболее распространенный метод, при котором пропуски заполняются средним значением по этому столбцу. Это удобно, но может быть неэффективно, если данные имеют выбросы.
- Медиана: лучше подходит для данных с выбросами, так как менее чувствительна к экстремальным значениям. Заполнение пропусков медианой помогает сохранить распределение данных.
- Модальное значение: этот метод используется для категориальных данных, когда пропуски заменяются наиболее часто встречающимся значением в столбце.

Рисунок 1. Пример импутации пропусков
Удаление дубликатов
Дубликаты в данных могут привести к искажению результатов анализа и моделирования. Методы для обнаружения и удаления дубликатов:
1. Обнаружение дубликатов:
- Для выявления дублирующихся строк используется специальный механизм, который сравнивает значения всех или определённых столбцов. Это позволяет быстро находить записи, которые полностью идентичны или имеют схожие характеристики.
2. Удаление дубликатов:
- После выявления дубликатов необходимо принять решение о том, как с ними поступить. Обычно удаляется повторяющаяся запись, оставляя только одну, что помогает предотвратить искажение статистики и моделей. Это особенно важно, когда дублирующиеся данные могут привести к переоценке или недооценке значимости определённых признаков.
Обработка выбросов
Выбросы — это аномальные значения, которые значительно отличаются от остальных данных. Они могут возникать как следствие ошибок измерений или же представлять собой настоящие вариации в данных. Методы для выявления и удаления выбросов:
1. Визуализация:
- Используйте графики для выявления выбросов. Гистограммы и диаграммы размаха помогут вам наглядно увидеть, какие значения значительно отклоняются от остальных.
2. Удаление по порогу:
- Установите логические границы для ваших данных и удалите значения, которые их превышают. Например, если у вас данные о возрасте, и вы знаете, что не должно быть людей старше 120 лет, удалите эти значения.
3. Замена выбросов:
- Если выбросы были обнаружены, замените их на медиану или другое приемлемое значение, чтобы сохранить общее распределение данных.
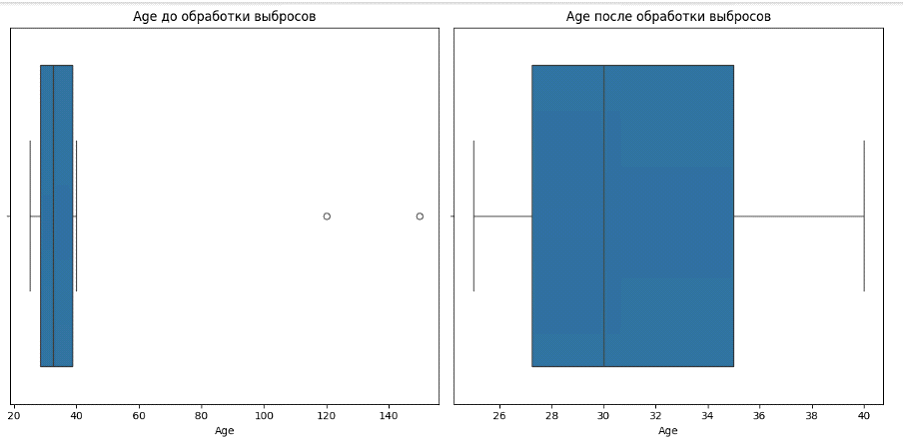
Рисунок 2. Пример обработки выбросов
Преобразование данных
Преобразование данных — это процесс подготовки и изменения исходных данных таким образом, чтобы они стали удобными и полезными для машинного обучения и анализа.
Нормализация
Нормализация — это приведение числовых признаков модели к одинаковому масштабу или диапазону. Данный процесс используют для того, чтобы все признаки (переменные) в данных были “на одном уровне”. Это предотвращает влияние на модель таких ситуаций, когда один признак выражается в тысячах, а другой — в единицах. [2]
Самым простым случаем нормализации является Min-Max Scaling.
Min-Max Scaling — это метод нормализации данных, при котором каждый элемент данных преобразуется в новое значение в определённом диапазоне, обычно от 0 до 1. Формула для применения Min-Max Scaling следующая:
![]()
где:
- x – исходное значение данных;
.gif) - нормализованное значение;
- нормализованное значение;- min(x) — минимальное значение в выборке;
- max(x) — максимальное значение в выборке.
Представим визуализацию примера использования данной нормализации на Рисунке 3.
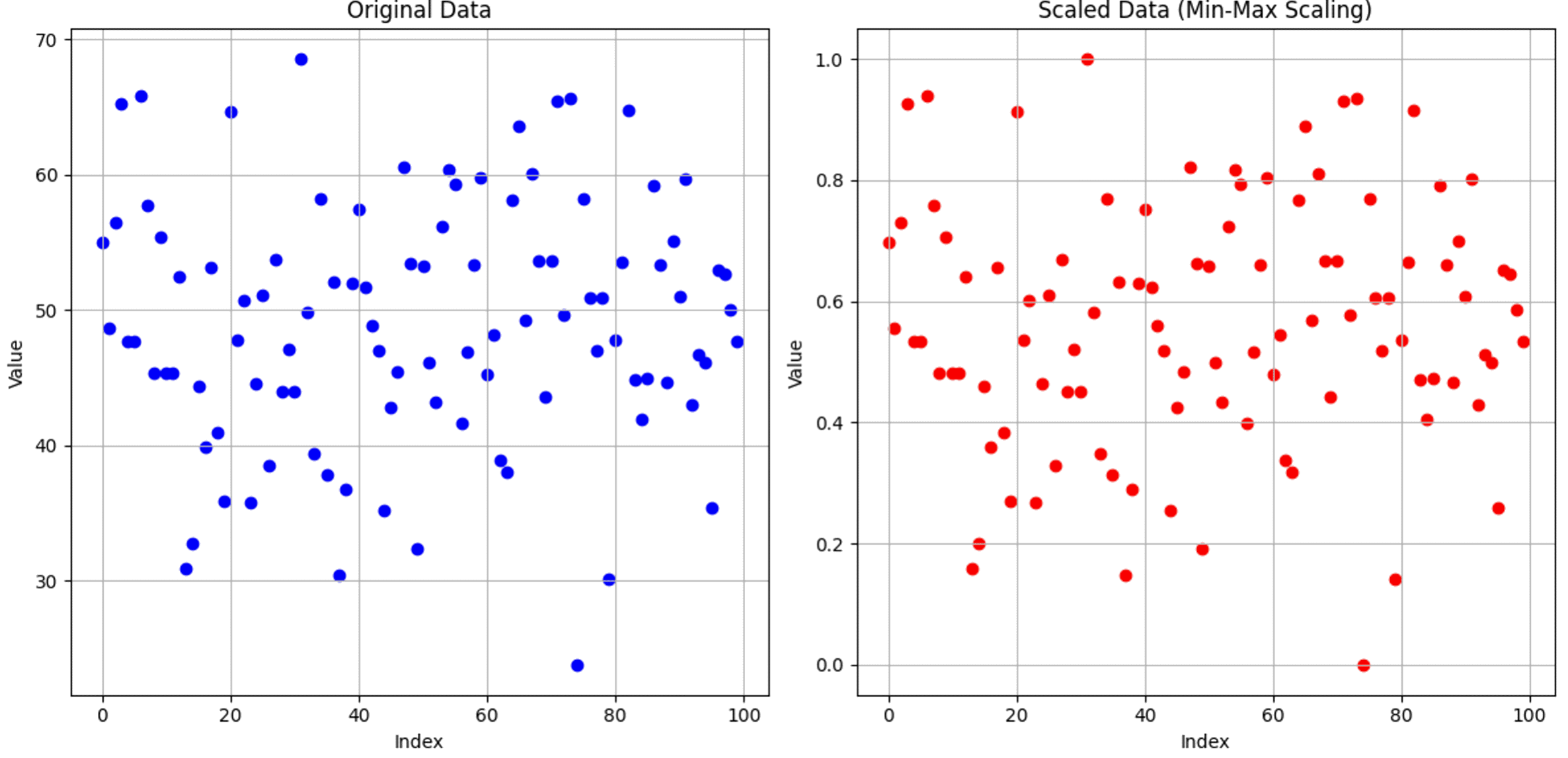
Как мы видим, интервал значений преобразовался от [0;70] до [0;1].
Стандартизация
Нормализация используется, когда возникает необходимость привести данные к одинаковому для всех признаков диапазону (например, [0, 1]).
Стандартизация же, в свою очередь, используется, когда данные имеют разные распределения или когда важно сохранить среднее и стандартное отклонение.
Стандартизация — это процесс, при котором данные преобразуются таким образом, чтобы каждый из признаков имел среднее значение 0 и стандартное отклонение 1.
При применении данного действия признаки принимают одинаковую “масштабируемость” и одинаково влияют на модель, независимо от того, в каком диапазоне они находятся.
Примером стандартизации является Z-score Normalization.
Z-score — это метод нормализации данных, который помогает привести данные к стандартному нормальному распределению, где среднее значение μ равно 0, а стандартное отклонение σ — 1. Такой подход используется, когда нужно, чтобы данные были “приведены к одинаковому масштабу”, но с сохранением их распределения. Формула данной стандартизации следующая:
![]()
где:
- x — исходное значение;
- z — нормализованное значение (Z-score);
- μ — среднее значение выборки;
- σ — стандартное отклонение выборки.
Пример стандартизации представлен на Рисунке 4.
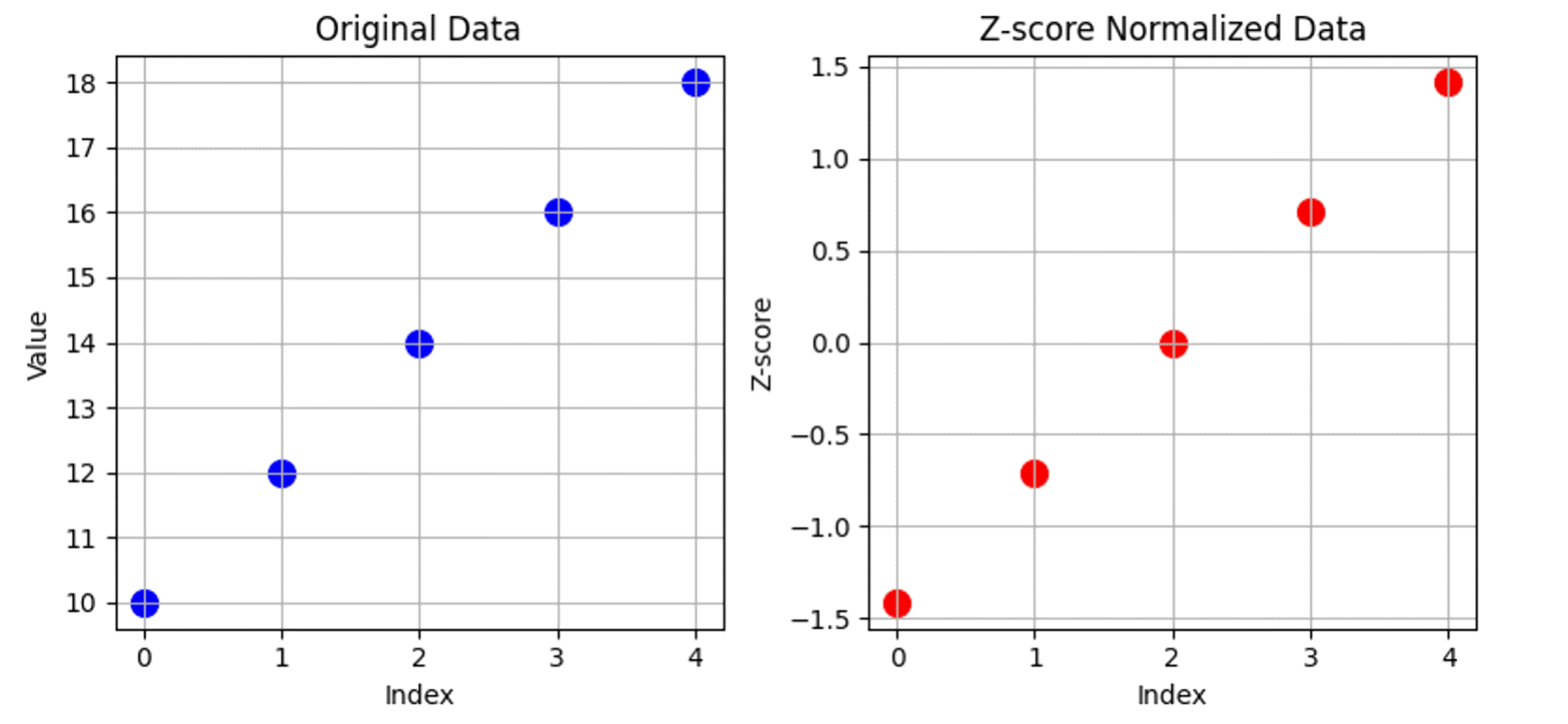
Заметим, что при стандартизации значения как-бы сравниваются со средним выборки, показывая, какое количество стандартных отклонений находится между конкретным значением и средним.
Преобразования категориальных переменных
Категориальные переменные — это такие переменные, которые представляют собой категории или группы. Например, “цвет” может быть категориальной переменной с такими значениями как “красный”, “синий” и “зелёный”.
При работе с категориальными переменными закономерно возникает вопрос: каким образом провести их непосредственный анализ. Для этого как правило производят преобразование категориальных переменных в числовые. Ниже представлен пример преобразования:

Создание новых признаков
Создание новых признаков — это процесс, при котором мы извлекаем дополнительную информацию из исходных данных, чтобы помочь модели лучше делать предсказания.
Приведем пример: если у нас есть количество покупок, которые клиент делает в месяц, мы можем создать новый признак, умножив это число на 12, чтобы получить количество покупок в год. Таким образом новый признак позволяет создать предсказания на протяжении долгого времени.
Уменьшение размерности
Уменьшение размерности — это важная техника в машинном обучении, которая используется для сокращения количества признаков в данных без потери значимой информации. Эта техника особенно полезна, когда в наборе данных много признаков (что может привести к таким проблемам, как проклятие размерности или разреженности), а также для улучшения скорости обучения моделей и уменьшения риска переобучения.
Иными словами, уменьшение размерности помогает упростить данные, оставив только самую важную информацию, которая будет полезна для предсказаний.
Рассмотрим основные методы уменьшения размерности.
- PCA — это линейный метод, который преобразует данные в новое пространство, выбрав новые оси (компоненты), которые максимизируют вариацию (дисперсию) данных. Эти новые оси называются главными компонентами.
- t-SNE — это метод уменьшения размерности, который хорошо работает с данными, имеющими нелинейные зависимости. Основная цель t-SNE — сохранить локальную структуру данных, то есть сохранять расстояния между похожими точками в низкоразмерном пространстве.
- UMAP — это метод уменьшения размерности, который похож на t-SNE, но с рядом преимуществ. Он предназначен для сохранения как локальной, так и глобальной структуры данных, при этом он более эффективен по времени и может работать с более большими наборами данных.
Балансировка классов
При работе с несбалансированными данными, где одна категория наблюдений значительно превышает по численности другую, модели машинного обучения могут стать предвзятыми и переоценивать большинство. Проблема дисбаланса классов особенно актуальна в задачах бинарной классификации, таких как обнаружение мошенничества или выявление редких заболеваний.
Существует несколько стратегий для борьбы с дисбалансом:
- Oversampling (увеличение меньшинства) – заключается в увеличении числа примеров меньшинства. Один из популярных методов – SMOTE (Synthetic Minority Over-sampling Technique), который синтетически создает новые примеры на основе имеющихся данных. [3]
- Undersampling (уменьшение большинства) – уменьшение числа примеров большинства, чтобы сбалансировать распределение классов. Этот метод уменьшает выборку класса, который доминирует, тем самым уменьшая общий объем данных.
Оба подхода имеют свои преимущества и недостатки. Oversampling может привести к переобучению, так как модель увидит несколько “клонированных” примеров, а undersampling рискует потерять важную информацию из большинства.
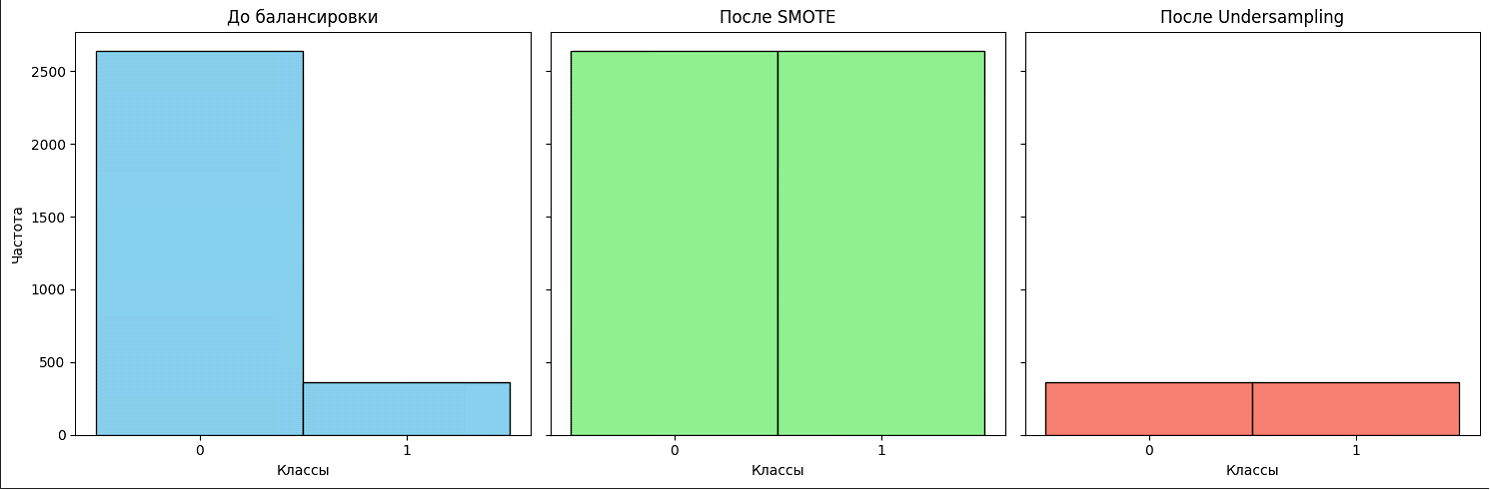
Данные до и после балансировки
На изображении представлено распределение данных до и после применения методов балансировки. До балансировки видно значительное преобладание основного класса, из-за чего модель плохо распознаёт редкий класс. После балансировки, с использованием методов, таких как SMOTE и RandomUnderSampler, оба класса представлены более равномерно. Это улучшает способность модели распознавать примеры редкого класса, что особенно важно для задач с несбалансированными данными.
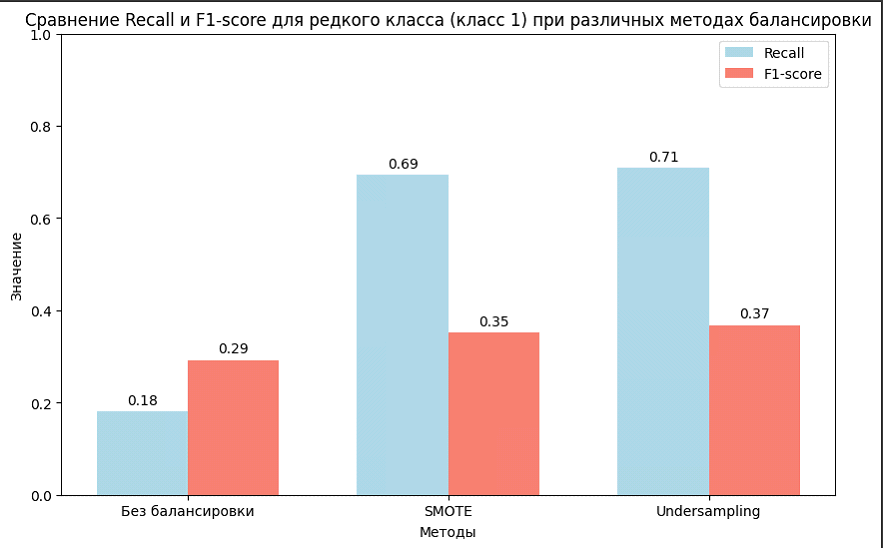
На столбчатой диаграмме показано, как балансировка данных с помощью SMOTE и RandomUnderSampler улучшает Recall и F1-score для редкого класса по сравнению с результатами без балансировки. Без балансировки модель демонстрирует низкий Recall (0.18) и F1-score (0.29), что отражает её слабую способность распознавать редкий класс, поскольку основная масса предсказаний относится к более частому классу.
После применения SMOTE Recall увеличивается до 0.69, а F1-score — до 0.35, что показывает улучшение точности и полноты для редкого класса. Метод RandomUnderSampler повышает эти показатели ещё больше, до 0.71 и 0.37 соответственно. Оба подхода значительно улучшают классификацию редкого класса, что особенно важно в задачах, требующих точного выявления малочисленных категорий, таких как аномалии или медицинская диагностика.
Практические советы:
- SMOTE подходит для данных с высоким количеством признаков, так как создает новые синтетические данные. Однако его следует использовать осторожно в задачах, где важна интерпретируемость данных, так как сгенерированные примеры могут усложнить их анализ.
- Undersampling рекомендуется применять, когда количество данных велико, и потеря части выборки не приведет к значительной потере информации. Он может быть особенно полезен при ограниченных ресурсах для обучения модели.
Заключение
Балансировка классов – важный шаг в предобработке данных, который позволяет улучшить качество моделей машинного обучения в задачах с дисбалансом данных. Использование методов oversampling и undersampling дает возможность корректировать несбалансированные выборки, что положительно сказывается на результатах.
Однако, важно помнить, что выбор метода балансировки зависит от типа задачи и характеристик данных. Кроме того, документирование всех шагов и использованных методов – неотъемлемая часть процесса, позволяющая сделать модель более воспроизводимой и понятной для других исследователей.
Библиографический список
- Абраменкова И. В., Круглов В. В. Методы восстановления пропусков в массивах данных // Программные продукты и системы. 2005. №2. URL: https://cyberleninka.ru/article/n/metody-vosstanovleniya-propuskov-v-massivah-dannyh (дата обращения: 18.11.2024).
- Никулин Владимир Николаевич, Канищев Илья Сергеевич, Багаев Иван Владимирович Методы балансировки и нормализации данных для улучшения качества классификации // КИО. 2016. №3. URL: https://cyberleninka.ru/article/n/metody-balansirovki-i-normalizatsii-dannyh-dlya-uluchsheniya-kachestva-klassifikatsii (дата обращения: 18.11.2024).
- Махсотова Цагана Валентиновна Исследование методов классификации при несбалансированности классов // Научный журнал. 2017. №5 (18). URL: https://cyberleninka.ru/article/n/issledovanie-metodov-klassifikatsii-pri-nesbalansirovannosti-klassov (дата обращения: 18.11.2024).