Любой проект в области анализа данных или машинного обучения начинается с этапа предобработки данных. Этот этап, часто называемый «feature engineering» (создание признаков), является критически важным для построения качественных моделей. Одна из самых распространенных задач на этом этапе — работа с категориальными признаками. Такие признаки описывают принадлежность объекта к определенной группе или классу: например, пол, страна проживания, тип товара, образовательная степень.
Алгоритмы машинного обучения — будь то линейная регрессия, решающее дерево или нейронная сеть — оперируют числами. Они не могут напрямую интерпретировать текстологические значения вроде «М» или «Саутгемптон». Наша задача — найти способ перевести эту категориальную информацию в числовую, не исказив при этом ее смысл. В этой статье мы решим практическую задачу по кодированию трех признаков из датасета «Титаник» и объясним теоретическую базу, стоящую за этим процессом.
Категориальные признаки делятся на два основных типа:
Номинальные (Nominal): Категории не имеют внутреннего порядка. Например, «Порт посадки» (Саутгемптон, Шербур, Куинстаун). Нет такого понятия, что «Шербур > Саутгемптон».
Порядковые (Ordinal): Категории имеют четкий, естественный порядок. Например, «Класс» (1-й, 2-й, 3-й) или «Уровень образования» (школа, бакалавр, магистр). Здесь 1-й класс объективно «выше» 3-го по уровню сервиса и комфорта.
Неправильное кодирование может ввести алгоритм в заблуждение. Если мы просто заменим порты посадки числами (Саутгемптон=1, Шербур=2, Куинстаун=3), модель может ошибочно решить, что между ними существует количественное отношение (например, что Куинстаун «в три раза больше» Саутгемптона), что бессмысленно.
Для корректного преобразования используются два основных метода, которые мы и применили в нашем задании.
1.1. Бинарное кодирование (Label Encoding для бинарных признаков)
Этот метод применяется к признакам, имеющим ровно две категории.
Принцип: Каждой категории присваивается число: 0 или 1.
Область применения: Идеально подходит для бинарных признаков, таких как «Пол» (М/Ж), «Есть ли домашнее животное?» (Да/Нет), «Прошел ли клиент целевое действие?» (Да/Нет).
Пример из задания: Для признака «Пол» мы применили простое правило:
‘М’ → 1
‘Ж’ → 0
Такой подход экономно использует пространство признаков (не создает новых столбцов) и однозначно разделяет объекты на две группы.
1.2. One-Hot Encoding (OHE) — Кодирование в виде «горячего» вектора
Это стандартный метод для работы с номинальными признаками, у которых нет внутреннего порядка.
Принцип: Для каждой уникальной категории внутри признака создается новый бинарный (0/1) столбец. Для каждого объекта 1 ставится в столбце, соответствующем его категории, а во всех остальных новых столбцах — 0.
Область применения: Номинальные признаки с тремя и более категориями, такие как «Порт посадки» или к примеру «Страна», «Марка автомобиля».
Пример из задания:
Пример представлен на рисунке 1.
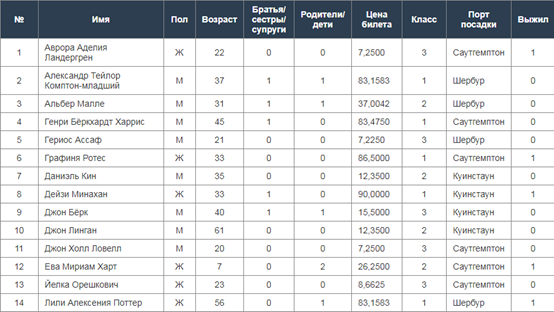
Рисунок 1
Исходный признак «Класс» имеет 3 категории: 1, 2, 3. Хотя он является порядковым, OHE также применим, особенно если мы не хотим, чтобы модель предполагала строгую линейную зависимость (иногда разница между 1-м и 2-м классом может быть значительнее, чем между 2-м и 3-м).
Процесс: Мы создали три новых признака: Класс_1, Класс_2, Класс_3.
Для пассажира 1-го класса: Класс_1=1, Класс_2=0, Класс_3=0.
Для пассажира 3-го класса: Класс_1=0, Класс_2=0, Класс_3=1.
Исходный признак «Порт посадки» имеет 3 категории: Саутгемптон, Шербур, Куинстаун.
Процесс: Мы создали три новых признака: Порт_Саутгемптон, Порт_Шербур, Порт_Куинстаун.
Для пассажира, севшего в Шербуре: Порт_Саутгемптон=0, Порт_Шербур=1, Порт_Куинстаун=0.
Важное замечание: После применения OHE исходный категориальный столбец удаляется из набора данных, чтобы избежать избыточности.
2. Постановка задачи
Нам был предоставлен датасет с информацией о 14 пассажирах Титаника (рисунок 1). Содержащиеся в нем категориальные признаки («Пол», «Класс», «Порт посадки») непригодны для непосредственного анализа алгоритмами машинного обучения.
Цель: Преобразовать эти три признака в числовой формат, руководствуясь следующими правилами:
Пол: Закодировать бинарно (‘М’ → 1, ‘Ж’ → 0).
Класс: Применить One-Hot Encoding, создав три dummy-переменных: Класс_1, Класс_2, Класс_3.
Порт посадки: Применить One-Hot Encoding, создав три dummy-переменных: Порт_Саутгемптон, Порт_Шербур, Порт_Куинстаун.
Результатом должна стать рисунок 2, где для каждого пассажира указаны его имя и новые, закодированные версии указанных признаков.
3. Описание решения
Решение задачи выполнялось в несколько последовательных шагов для каждого пассажира из исходной Таблицы 1.
Шаг 1: Кодирование признака «Пол».
Для каждого пассажира мы смотрели на значение в столбце «Пол» и заменяли его на 1 (если ‘М’) или 0 (если ‘Ж’). Например:
Джон Линган (№1): ‘М’ → 1.
Аврора Аделия Ландергрен (№2): ‘Ж’ → 0.
Шаг 2: One-Hot Encoding для признака «Класс».
Для каждого пассажира мы анализировали его класс и проставляли 1 в соответствующем столбце, и 0 — в двух других.
Джон Линган (№1): Класс = 1 → Класс_1=0, Класс_2=1, Класс_3=0.
Аврора Аделия Ландергрен (№2): Класс = 2 → Класс_1=0, Класс_2=1, Класс_3=0.
Графиня Ротес(№4): Класс = 3 → Класс_1=1, Класс_2=0, Класс_3=0.
Шаг 3: One-Hot Encoding для признака «Порт посадки».
Аналогично предыдущему шагу, мы создали три бинарных столбца для портов.
Графиня Ротес(№4): Порт = Саутгемптон → Порт_Саутгемптон=1, Порт_Шербур=0, Порт_Куинстаун=0.
Альбер Малле (№3): Порт = Шербур → Порт_Саутгемптон=0, Порт_Шербур=1, Порт_Куинстаун=0.
Джон Линган (№1): Порт = Куинстаун → Порт_Саутгемптон=0, Порт_Шербур=0, Порт_Куинстаун=1.
Результат: В результате ручного применения этих правил для 4 пассажиров была заполнена Таблица 2. Её фрагмент представлен ниже для наглядности (рисунок 2).

Рисунок 2
Выводы
Проделанная работа наглядно демонстрирует важность и необходимость этапа предобработки категориальных данных. Путем применения всего двух методов кодирования — бинарного и One-Hot Encoding — мы превратили текстологическую информацию, непонятную для машины, в строгий числовой формат.
Корректность представления: One-Hot Encoding позволил избежать навязывания ложного порядкового соотношения между номинальными признаками (порты) и нивелировать возможный нелинейный эффект порядкового признака (класс).
Готовность к анализу: Полученная в Таблице 2 матрица признаков является чистой и готовой к использованию. Её можно напрямую подавать на вход алгоритмам машинного обучения для решения задач классификации (например, предсказание выживания) или регрессии.
Универсальность методов: Рассмотренные подходы являются стандартными и широко применяются в индустрии. Понимание их принципов — фундаментальный навык для любого специалиста по data science.
В реальных проектах этот процесс автоматизируется с помощью библиотек, таких как Pandas (pd.get_dummies()) или Scikit-learn (OneHotEncoder), что позволяет обрабатывать тысячи строк за доли секунды. Однако ручное выполнение, как в этом задании, закрепляет понимание сути преобразования, что неизменно важнее механического владения инструментом.