Введение
В сети интернет находится огромное количество текстовых данных которые могут быть проанализированы и в дальнейшем использованы для CASE технологий. Этим занимаются большие поисковые системы, такие как Google, Yandex, Yahoo и другие. Они обладают большими вычислительными мощностями и могут позволить себе анализировать большое количество данных из интернета.
В современном мире, постоянно появляются все новые и новые технологии которые изменяют концепции работы web-приложений и их разработку. Чем быстрее они совершенствуются, тем быстре совершенствуются системы парсинга. Сейчас в них уже применяется технологии “Machine Learning” (Машинное обучение) для корректриовки анализа данных. Путем лексического разбора ответ от web-серверов на http запрос, происходит аналитика разного типа данных.
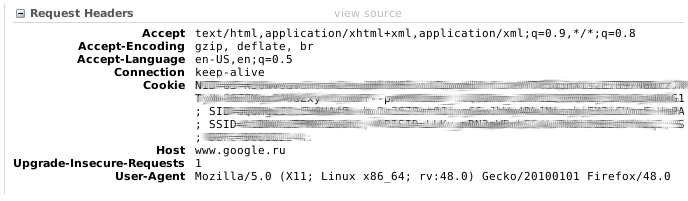
Изображение 1 – “Запрос от интернет обозревателя Mozilla Firefox к http://google.ru/”
Запрос представленный на изображении(см. изобр. 1) имеет 8 полей которые передаются сервера для получение данных от него. В данном случае это самый первый запрос обращения к серверу который передает основные данные клиента для взаимодействия.
|
№ |
Название |
Краткое описание |
|
1 |
Accept |
Ожидаемый тип данных которые вернет запрос |
|
2 |
Accept-Encoding |
Ожидаемая кодировка |
|
3 |
Accept-Language |
Ожидаемый язык |
|
4 |
Connection |
Опция для контроля состоянием текущего соединения |
|
5 |
Cookie |
Данные которые хранит клиент с предыдущей сессии |
|
6 |
Host |
Адрес сервера к которому подключаемся |
|
7 |
Upgrade-Insecure-Request |
CSP-атрибут который переводит соедиение с http на https |
|
8 |
User-Agent |
Информация о клиенте |
Таблица 1 – “Поля HTTP запроса”
Поле “Accept” содержит типы данных которые клиент ожидает получить в ответе сервера. Они задаются путем MIME типов. MIME (англ. Multipurpose Internet Mail Extensions) – это стандарт который описывает передачу различных типов данных. Для лексического разбора и последующей аналитики подходят следующие типы MIME данных:
|
№ |
Название |
Краткое описание |
|
1 |
text/cmd |
Команды |
|
2 |
text/css |
Таблицы стилей CSS |
|
3 |
text/html |
HTML |
|
4 |
text/javascript |
JavaScript |
|
5 |
text/plain |
Обычный текст |
|
6 |
text/php |
Скрипт на PHP |
|
7 |
text/xml |
Данные в формате XML |
Таблица 2 – “Типы MIME подходящие для лексического анализа”
Все типы данных представленные в таблице 2, являются обычным текстом. Различает их, формат и назначение. Они могут быть очень просто лексически распознаны и проанализированы.
На изображении 2, представлен ответ от web-сервера “google.ru”, на запрос представленный на изображении 1. Как можно заметить поле “Content-Type” содержит значение “text/html, charset=UTF-8”. значит, что мы получили в ответ HTML файл в кодировке UTF-8. Данный тип файла может быть лексически разобран и проанализирован.
.png)
Изображения 2 – “Ответ от http://google.ru/”
Сервер, так же может возвращать и другие типы данных с которыми невозможно работать с помощью лексического разбора и последующих аналитических разборов их контекста. На изображении 3, показан ответ от сервера в формате “image/png”. Это означает, что сервер вернул клиенту изображения в формате png. Формат PNG(Portable Network Graphics) представляет собой бинарный тип растровых изображений который не может быть проанализирован как текст.
.png)
Изображение 3 – “Сервер вернул картинку в формате png”
Изображения так же представляют большой интерес для их аналитики и разбора. Но осуществляется это инструментами для аналитики на основе технологий машинного обучения(machine learning). Один из существующих инструментов аналитики изображений был разработан компанией Microsoft. На основе этих технологий был разработан сервис “Emotional API”, с помощью которого можно передать графическое изображение и получить ответ в виде данных в формате JSON, являющихся результатом распознания изображения. Пример использования сервиса Emotional API представлен на изображении 4.
.png)
Изображение 4 – “Microsoft Emotional API”
Проблематика
Аналитика большого количества интернет ресурсов в промышленном масштабе происходит при помощи больших вычислительных мощностей. Из-за неограниченно большого количества ресурсов лексический разбор происходит при помощи поисковых роботов, которые анализируют встречающиеся на их пути интернет сайты. В итоге создаются базы данных на несколько миллиардов значений, которые подлежат глубокой и точной аналитике. Google использует сотни тысяч таких поисковых роботов для постоянного расширения своей базы и более точной аналитики. В дальнейшем такие данные используются компанией Google для предоставления “умной” рекламы направленной на определенные круги пользователей, которые будут заинтересованы в этой рекламе. Что в итоге позволяет компаниям покупающим рекламу у Google, получить аудиторию заинтересованную именно в их продукции или услугах.
Но не всегда требуется аналитика в больших масштабах. Реализация систем для более узких данных в списках выбранных ресурсов, чрезвычайно дорогой проект для малых и средних компаний. Модераторы различный социальных сетей, групп, форумов использует в своей работы средства обычного поиска или специализированные средства предоставленный платформой на которой они работают. Они сталкиваются с сотнями тысяч комментариев или публикаций которые нужно просматривать в ручную или пользоваться обычным контекстным поиском. Но их действия являются обычной рутиной и повторяющейся работой которую автоматизировать при помощи средств анализа текстов, очень проблематично и неактуально. Проблема невозможности автоматизации, заключается сложности анализа текста который может писаться с ошибками в грамматике и умышленному нарушению построения слов с ошибками. Например удаление из публикаций нецензурных выражений может быть очень затруднена тем, что слова написанные с обычной точкой между буквами или пропущенной буквой, потеряют грамматический смысл, а нецензурное значение сохранят, тем самым удалены они не будут. Для более интеллектуального поиска существуют регулярные выражения.
На изображении 5, предоставлен текст регулярного выражения на основе которого может быть разобрано обычное и искаженное слово “привет”.
![]()
Изображение 5 – “Регулярное выражения для поиска слова ‘привет’”
За основу взяты согласные буквы которые несут основной смысл этого слова. И если мы уберем их или попытаемся заменить, чтобы скрыть свое слова от аналитики мы можем использовать искажение, например:
-
“првет” – уберем первую гласную, смысл остается понятным, но стандартным анализатором это распознано не будет.
-
“превет” – слово написанное с ошибкой так же, не будет разобрано при помощи анализа роботом.
-
“првт” – слово написанное без согласных.
Все эти 3 примера будут разобраны при помощи регулярного выражения изображение. Пример применения регулярного выражения показан на изображении 6.
![]()
Изображение 6 – “Разбор правильного и неправильного слова ‘привет’ на основе регулярного выражения”
Такой разбор верен в некоторых случаях, и представляет достаточную гибкость для поиска даже скрытых слов. Но в случае анализа слова “привет”, если в тексту встретится аббревиатура “ПРВТ”, то распознание ее как слова “привет” будет ошибкой.
Агентства заинтересованные в оценке спроса автомобилей, могут получить такую статистку путем просмотра интернет ресурсов и ручного анализа цен и количества объявлений о продаже того или иного автомобиля. Полученные структуры данных могут быть:
-
Проанализированы моментально
-
Добавлены в базу данных для накопления информации для сложных и более долговременных аналитик.
Например аналитика цен автомобилей на сайтах где их публикуют может быть сохранена в базу данных, и спустя несколько лет проанализирована на основе имеющихся данных.
Возьмем для примера автомобиль Toyota Corolla 2009 года выпуска. На сайте “авто.ру” цены, на этот автомобиль очень сильно различаются и их диапазон составляет примерно 100 тысяч рублей. Средняя стоимость автомобиля 350 тысяч рублей. Мы можем проанализировать все представленные варианты на сайтах продаж подержанных автомобилей. Скажем в диапазоне 1-2 месяца. После аналитики от 100 объявлений о продаже автомобиля мы можем вычислить среднее значение цены на автомобиль. Выполнив эту аналитику сейчас, а следующую через 1 месяц, мы сможем увидеть колебания цены, которая отражает усредненное значения желаемой цены продажи этого автомобиля. Составление и просмотр объявлений даже по одной тематике, это очень трудоемкая рутинная задача.
Принцип работы
Все данные которые находятся в интернете, представляют собой чередование блоков которые содержат различную дополнительную информацию. Для её аналитики необходимо выявить порядок действий:
-
Выявить чередования блоков информации.
-
Разметить чередования блоков и принцип их устройства
-
Составить лексический анализатор на основе существующей схемы
-
Выполнить лексический разбор существующего интернет ресурса
Для реализации данной идеи была выбрана платформа интернет обозревателя Mozilla Firefox, которая позволяет разрабатывать специализированные подключаемые модули или “плагины”(от англ. plug-in – подключать). Интернет обозреватель или браузер (от англ. web browser – web-обозреватель). Браузер способен обрабатывать и посылать запросы через http/https протокол и содержит базовые инструменты обработки запросов и ответов. Что позволит выполнить анализ в локальных масштабах, без больших вычислительных мощностей и ресурсных затрат на операцию. Все блоки информации, помечаются путем визуального просмотра кода, в дальнейшем автоматически анализируются и добавляются в базу данных.
Интернет обозреватель Mozilla Firefox распространяется под лицензией MPL 2.0 и использует свободный движок вывода веб-страниц Gecko. Лицензия MPL(Mozilla Public License) позволяет разрабатывать на основе данного продукта другие программные продукты. Основной из главных особенностей интернет обозревателя, является поставка в стандартном комплекте, гибкого механизма расширений, которые позволяют пользователям модифицировать браузер в соответствии их требованиям. Почти с начала своего существования Firefox является достаточно гибким браузером с широкими возможностями настройки: пользователь может устанавливать дополнительные темы, изменяющие внешний вид программы, плагины и расширения, добавляющие новую функциональность. Эта расширяемость достигается, в основном, за счёт использования в интерфейсе разработанного исключительно для Gecko языка разметки XUL и используемых в Web JavaScript и CSS. Mozilla Firefox официально выпускается для GNU/Linux, Windows, MacOS, и Android. Доступны готовые сборки для FreeBSD и множества других UNIX-подобных операционных систем, а также BeOS. Исходный код браузера является открытым и распространяется под тройной лицензией GPL/LGPL/MPL (Mozilla Public License).По мнению калифорнийской компании Sauce Labs на сентябрь 2014 года — разработчика платформы для тестирования приложений — в Firefox ошибки возникают реже, чем в других интернет обозревателях.
Коэффициент ошибок в Firefox, по сравнению с другими браузерами представлен в таблице 3.
|
№ |
Название |
Коэффициент ошибок |
|
1 |
Firefox |
0,11 % |
|
2 |
Google Chrome |
0,12 % |
|
3 |
Opera |
0,125 % |
|
4 |
Safari |
0,15 % |
Таблица 3 – “Mozilla Firefox в сравнении с другими браузерами по количеству возникновения ошибок.”
За базовую систему лексического анализатора, была взята технология ANTLR, работающая по принципу LL-грамматики. Контекстно-свободная грамматика (КС-грамматика, бесконтекстная грамматика) — частный случай формальной грамматики , у которой левые части всех продукций являются одиночными нетерминалами (объектами, обозначающими какую-либо сущность языка (например: формула, арифметическое выражение, команда) и не имеющими конкретного символьного значения). Смысл термина «контекстно-свободная» заключается в том, что есть возможность применить продукцию к нетерминалу, в отличие от общего случая неограниченной грамматики Хомского, не зависит от контекста этого нетерминала. Язык, который может быть задан КС-грамматикой, называется контекстно-свободным языком или КС-языком. На изображении 5, показан участок разметки HTML документа.
.png)
Изображение 5 – “разметка HTML документа”
Разобранный итоговый документ при помощи технологий ANTLR, представляет собой иерархическую структуру и показан на изображении 6. Преимущества ANTLR, заключаются в:
-
Использование единой нотации для описания лексических и синтаксических анализаторов.
-
Предоставление сообщений об ошибках и восстановление после них.
-
Удобство работы с абстрактным синтаксическим деревом.
-
Свободное программное обеспечение.
-
Применение нисходящего, а не восходящего анализа.
-
Наличие специальных средств которые помогают в разработке ANTLR Works и ANTLR Studio.
.png)
Изображение 6 – “Дерево лексически разобранного текста”
Наличие графических средств разработки помогает упростить разработку сложных лексических анализаторов. Пример работы в ANTLR Works, показан на изображении 7.
.png)
Изображение 7 – “Работа с ANTLR Works”
Заключение
В результате проведенных исследований, были получены следующие результаты и сделаны выводы:
-
Проанализированы и применены на практике шаблоны ANTLR и получено итоговое дерево результатов парсинга.
-
Разработаны примеры взаимодействия системы расширений Mozilla Firefox и генератора LL-грамматики ANTLR при помощи ANTLR Works.
-
Определено, что Mozilla Firefox это надежная и гибкая платформа для разработки программных решений для обработки данных через интернет. Предоставляет широкий функционал для работы с HTTP/HTTPS протоколами.
-
Установлены возможности гибкого языка интерфейсов XUL, который входит в стандартную поставку Mozilla Firefox. Позволяет разрабатывать сложные интерфейсы программ которые работают на платформе Firefox.
Разработка визуального средства, для составления лексических анализаторов или “парсеров” на основе технологий ANTLR и Mozilla Firefox позволяет эффективно выполнять следующие задачи:
-
Агрегирование данных с интернет ресурсов и для сохранения в базы данных или для мгновенная обработка.
-
Поиск сложных конструкций в текстовых данных.
-
Мгновенное редактирование документа, на основе визуального шаблона.
Библиографический список
- “Сервис распознания эмоций по фотографии” [Электронный ресурс] - http://blogs.microsoft.com/next/2015/11/11/happy-sad-angry-this-microsoft-tool-recognizes-emotions-in-pictures/
- “База знаний Mozilla Firefox” [Электронный ресурс] - https://developer.mozilla.org/en-US/
- “Описание стандартов интернета” [Электронный ресурс] – https://www.w3.org/
- А. Ахо, Дж. Ульман. Теория синтаксического анализа, перевода и компиляции. Т. 1. Пер. с англ. В.Н. Агафонова под ред. В. М. Курочкина. М.: Мир, 1978. 614 с.
- Терренс Парр “The Definitive ANTLR 4 Reference” - 2012 г. – 301 с.
- Фридл, Дж. Регулярные выражения. — СПб.: «Питер», 2001. — 352 с.