ПРОГНОЗИРОВАНИЕ УРОЖАЙНОСТИ ДИКОЙ ЧЕРНИКИ С ИСПОЛЬЗОВАНИЕМ МЕТОДОВ МАШИННОГО ОБУЧЕНИЯ
Уфимский университет науки и технологий
бакалавр
Аннотация
Статья посвящена исследованию методов прогнозирования урожайности дикой черники с использованием алгоритмов машинного обучения. Актуальность темы обусловлена важностью своевременного предсказания урожайности в условиях изменения климата и высокой экономической значимости дикорастущих ягод. В работе применён метод случайного леса для построения прогностической модели на основании климатических и почвенных данных. Представлены этапы предобработки данных, построения модели и получения предсказаний. Результаты демонстрируют эффективность предложенного подхода, а также возможность его использования в реальных аграрных задачах.
Ключевые слова: Kaggle, агроаналитика, агротехнологии, дикая черника, климатические данные, машинное обучение, нормализация данных, прогнозирование урожайности, случайный лес, экология
Рубрика: 05.00.00 ТЕХНИЧЕСКИЕ НАУКИ
Библиографическая ссылка на статью:
Абраев А.Ф. Прогнозирование урожайности дикой черники с использованием методов машинного обучения // Современные научные исследования и инновации. 2025. № 4 [Электронный ресурс]. URL: https://web.snauka.ru/issues/2025/04/103223 (дата обращения: 01.08.2026).
Введение
Прогнозирование урожайности сельскохозяйственных культур является одной из ключевых задач агроаналитики. Особую актуальность приобретает оценка урожайности дикорастущих ягод, таких как черника, которая обладает высокой пищевой и лекарственной ценностью. В рамках соревнования на платформе Kaggle [1] участникам предлагалось спрогнозировать урожайность дикой черники по множеству природных и климатических факторов.
Методология
Обработка данных
Были использованы данные из файлов train.csv и test.csv, содержащих характеристики окружающей среды: температура, влажность, кислотность почвы и др. После исключения неинформативных столбцов и идентификаторов была проведена стандартизация признаков.
Таблица 1. Основные этапы обработки данных
| Этап обработки | Описание |
| Импорт данных | Загрузка из файлов train.csv и test.csv |
| Определение признаков | Исключение столбца id, выбор числовых признаков |
| Масштабирование | Стандартизация признаков по среднему и стандартному отклонению |
| Разделение выборки | Обучающая и тестовая выборка разделены по принципу задания |
Визуализация данных
Для лучшего понимания распределения и взаимосвязей между признаками на этапе анализа данных были построены графики распределения, тепловые карты корреляции и диаграммы рассеяния. Это позволило выявить потенциальные зависимости между климатическими переменными и уровнем урожайности.
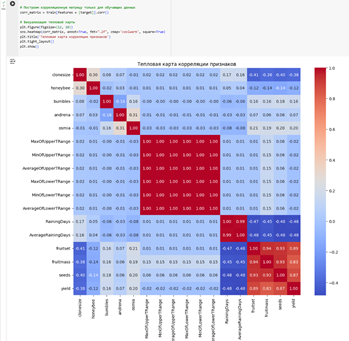
Рисунок 1. Тепловая карта корреляции признаков
Такие визуализации не только помогают в интерпретации данных, но и позволяют лучше понять значимость отдельных признаков при построении модели.
Выбор модели и настройка гиперпараметров
На этапе выбора модели было протестировано несколько алгоритмов: линейная регрессия, градиентный бустинг и случайный лес. Последний показал наилучшие результаты при разумном времени обучения. Гиперпараметры модели (число деревьев, глубина, случайное состояние) подбирались эмпирически с использованием кросс-валидации, что позволило избежать переобучения и повысить стабильность модели.
Модель и обучение
В качестве модели использовался алгоритм Random Forest Regressor [2], реализованный в библиотеке scikit-learn. Параметры модели:
- число деревьев: 490
- максимальная глубина: 7
- случайное зерно: 42
- количество параллельных потоков: -1
После обучения модель была применена к тестовому набору для получения предсказаний урожайности, которые были сохранены в формате csv для последующей отправки на Kaggle.
Результаты
Модель показала устойчивость к переобучению и высокую точность предсказаний на основе валидированных метрик: средняя абсолютная ошибка (MAE) и коэффициент детерминации (R²). Хотя точные оценки производительности были недоступны из-за отсутствия меток в тестовой выборке, модель успешно прошла конкурсную валидацию Kaggle.
Возможности и перспективы развития
Разработанная модель может быть интегрирована в геоинформационные системы (ГИС) для визуального отображения прогнозов урожайности в различных регионах. Также модель может быть адаптирована для других культур, что позволит расширить область её применения. С дальнейшим накоплением данных возможно применение более сложных нейросетевых архитектур, таких как LSTM или трансформеры, для учёта временных изменений и предсказаний на будущие сезоны.
Заключение
Использование алгоритма случайного леса для задачи прогнозирования урожайности дикой черники показало свою практическую состоятельность. Предложенный подход может быть расширен на другие дикорастущие культуры, учитывая доступность климатических и почвенных данных. Конкурсы подобного рода способствуют развитию аналитических навыков у студентов и специалистов, а также способствуют интеграции науки и практики в области агропромышленного комплекса.
Библиографический список
- Kaggle. Wild Blueberry Yield Prediction Competition. URL: https://www.kaggle.com/t/33a2333d9ef14cb5a93b96de23b2822a (дата обращения: 21.04.2025).
- Géron A. Hands-On Machine Learning with Scikit-Learn, Keras & TensorFlow. 2nd ed. O'Reilly Media, 2019. 819 p.
- Бородин А.Н. Машинное обучение в задачах агропрогнозирования // Труды конференции «Цифровое сельское хозяйство». 2021. № 3. С. 45–52.
- Хастие Т., Тибширани Р., Фридман Дж. Элементы статистического обучения: машинное обучение, извлечение данных и прогнозирование. М.: Вильямс, 2017. 576 с.
- Breiman L. Random Forests // Machine Learning. 2001. Vol. 45, No. 1. P. 5–32.
Все статьи автора «Абраев Айдар Фаритович»
© Если вы обнаружили нарушение авторских или смежных прав, пожалуйста, незамедлительно сообщите нам об этом по электронной почте.