РАЗРАБОТКА АЛГОРИТМА ПОИСКА ИНФОРМАЦИИ ИЛИ ИНФОРМАЦИОННОГО ОБЪЕКТА В ТЕКСТЕ
Московский государственный технический университет имени Н. Э. Баумана
студент кафедры «Медико-технический менеджмент»
Аннотация
В статье продемонстрированы программные алгоритмы исследования источников информации, характеризующих отечественный рынок медицинских изделий, на примере исследования рынка имплантируемых кардиостимуляторов. Рынок имплантируемых кардиостимуляторов отличается широким диапазон разновидностей изделий и поэтому хорошо подходит для тестирования разработанного алгоритма. Пример показывает способность алгоритма отличать разновидности кардиостимуляторов: от разных производителей, имплантируемых дефибрилляторов от внешних, а также подвиды - одноканальные, двухканальные, трехканальные (для применения ресинхронизирующей терапии).
Ключевые слова: анализ данных, маркетинговые исследования, текстовые документы
DEVELOPMENT OF AN ALGORITHM OR SEARCH FOR INFORMATION IN THE TEXT INFORMATION OBJECT
Bauman Moscow State Technical University
student of the department "Medical and technical management"
Abstract
The article demonstrated software algorithms study the sources of information that characterize the domestic market of medical devices, as an example of research of the market of implantable cardiac pacemakers. Market implantable pacemaker has a wide range of types of products and is therefore well suited for testing the developed algorithm. The example shows the ability of the algorithm to distinguish between varieties of pacemakers from different manufacturers of implantable defibrillators from outside, as well as subspecies - one-channel, two-channel, three-channel (for use of cardiac resynchronization therapy).
Keywords: data analasys, marketing research, text documents
Рубрика: 05.00.00 ТЕХНИЧЕСКИЕ НАУКИ
Библиографическая ссылка на статью:
Рябов А.В. Разработка алгоритма поиска информации или информационного объекта в тексте // Современные научные исследования и инновации. 2016. № 6 [Электронный ресурс]. URL: https://web.snauka.ru/issues/2016/06/69146 (дата обращения: 31.07.2026).
Научный руководитель: Аполлонова И.А,. к.т.н,
заместитель заведующего кафедрой «Медико-технический менеджмент»
Ранее были исследованы и выделены основные препятствия при проведении анализа баз данных с помощью программных средств, поставляемых совместно со стандартным офисным пакетом [1]. Ниже представлены основные из них:
– ошибки в наименовании изделия или указание наименования в транскрипции;
– представление в одном лоте сразу несколько видов медицинских изделий;
– общее наименование изделий без указания производителя или модели.
Исходя из этого к разрабатываемому алгоритму были представлены следующие требования:
– определение по базам данных объема закупленного «наименования» товара, с учетом различных вариантов указания «наименования» в лоте;
– определение средней стоимости «наименования» товара, с учетом расположения нескольких изделий в одном лоте;
– конкретизация типа изделия по косвенным характеристикам, указанным в лоте.
Переходя к обзору алгоритма, следует заметить, что его использование для определения показателей, характеризующих рынок определенного изделия, не является полностью автоматическим и требует от пользователя знания по крайней мере основных игроков сегмента и базовых знаний о разновидностях входящих в него изделий.
На рисунке 1 представлена блок – схема работы алгоритма.
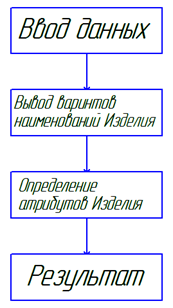
Рис. 1. Блок – схема работы алгоритма.
На этапе ввода информации алгоритм обрабатывает поле базы данных, в котором указывают наименование товара, работ, услуг. Задача локального алгоритма сводится к нахождению всех наименований товаров в разных формах его написания.
Для выявления наименований предложено использовать разные алгоритмы под разные условия поиска: в условиях, когда сегмент представлен в основном изделиями зарубежного производства, используется алгоритм поиска латинских символов. Причем для того, что бы избежать попадания в одну переменную сразу нескольких наименования, было допущено, что наименования между собой имеют кириллицу или знаки пунктуации. Шаги локального алгоритма представлен ниже:
1) Ввод данных – строка лота из поля «наименование товаров работ и услуг»:
«Духкамерный кардиовертер-дефибриллятор имплантируемый Lumax 340DR-T в комплекте с электродами Linox S65, Selox SR53 и двумя интродьюсерами»
2) Преобразование строки:
«**** ****-**** **** Lumax 340 DR-T * **** * **** Linox S65* Selox SR53 * **** ****»
3) Разбиение строки по разделителю и загрузка в список:
['Lumax 340 DR-T', 'Linox S65', 'Selox SR53']
4) Передача каждого элемента списка в переменную имени (наименования изделия).
На этапе вывода вариантов наименований изделий, пользователю необходимо определить, что из списка представленных наименований будет относится к исследуемому сегменту рынка, а также соотнести различные написание наименования изделия с единственно правильным.
Этап определения атрибутов является самым длительным из остальных, так как требует большого количества итераций по строкам лота, которое увеличивается соответственно объему базы данных.
Идея локального алгоритма заключается в нахождении пересечений множеств списков, элементами которых являются отдельные слова в строках лотов. Лоты выбираются из условия, что они содержат общее для них наименование изделия. Информация, которая чаще всего встречается в лотах (кроме названия изделия), будет являться общим пересечением множеств списков. Такая информация используется как атрибут изделия. Шаги работы локального алгоритма представлен ниже.
а) «Имплантируемый кардиовертер-дефибриллятор MAXIMO II CRT-D для ресинхронизирующей терапии с принадлежностями (арт. D284TRK)»
б) «Имплантируемый кардиовертер-дефибриллятор для ресинхронизирующей терапии Maximo II CRT-D»
в) «Имплантируемый кардиовертер-дефибриллятор Maximo II CRT-D. (Цифровой имплантируемый кардиовертер-дефибриллятор для ресинхронизирующей терапии с системой удаленного мониторинга пациента в комплекте с электродами и интродъюссерами)»
2) Нахождение пересечения множеств и выбор пользователем необходимого и достаточного варианта пересечения для определения модели изделия по его атрибутам: «Имплантируемый кардиовертер-дефибриллятор MAXIMO II CRT-D»
Имея все варианты написания наименования изделия, а также его атрибуты, можно переходить к конкретизации типа изделия по косвенным характеристикам, указанным в лоте.
Последний этап заключается в итерации по всем лотам, при совпадении атрибутов и наименования изделия, алгоритм добавляет информацию, как показано на рисунке 2.
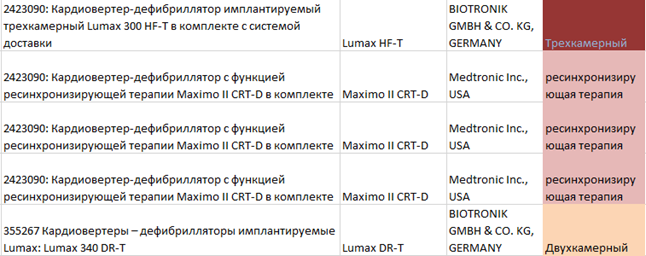
Рис.2. Пример преобразованной базы данных
Метод определения средней стоимости товара заключается в нахождении распределения цен и отсечении ценовых значений, величина которых превосходит допустимый интервал.
Таким образом были разработаны алгоритмы и решены поставленные задачи по нахождению необходимой информации.
Библиографический список
- Виленский А.В., Хрусталев А.В., Самородов А.В. Особенности исследования российского рынка медицинских изделий // Ремедиум. декабрь 2012.
- Боярский, К.К. Введение в компьютерную лингвистику: учеб. пособие / К.К. Боярский. – СПб: НИУ ИТМО, 2013. – 72 с
- Ягунова, Е.В. Слово – коллокация – синтаксические конструкции – текст. Единица анализа и контекст / Е.В. Ягунова //Автоматическая обработка текстов на естественном языке и компьютерная лингвистика : учеб. пособие / Е.И. Большакова [и др.]. – М.: МИЭМ, 2011. — 272 с. – С. 17–43.
Все статьи автора «Рябов Артем Вадимович»
© Если вы обнаружили нарушение авторских или смежных прав, пожалуйста, незамедлительно сообщите нам об этом по электронной почте.