ВИКОРИСТАННЯ МЕТОДУ ПРЯМОГО ПЕРЕКЛАДУ В СИСТЕМІ АВТОМАТИЗОВАНОГО ПЕРЕКЛАДАЧА
1Національний технічний університет України "Київський політехнічний інститут", доктор технічних наук, професор кафедри АУТС
2Національний технічний університет України "Київський політехнічний інститут", магістрант кафедри АУТС
Аннотация
Стаття присвячена проблемі розробки системи автоматизованого перекладу. Розглянута структура бази даних для словника. Запропоновано алгоритм перекладу текстів з однієї мови на іншу. Представлені запити до бази даних для перекладу окремих слів та текстів.
USING DIRECT TRANSLATION IN COMPUTER-AIDED TRANSLATION
1National Technical University of Ukraine Kiev Polytechnic Institute, PhD (doktor nauk), Professor, Department AUTS
2National Technical University of Ukraine Kiev Polytechnic Institute, master degree student, Department AUTS
Abstract
The article deals with the development of computer-aided translation. Considered the structure of the database for the dictionary. Suggested the algorithm of texts translation from one language to another. Presented database requests for the translation of individual words and text.
Keywords: computer-aided translation
Рубрика: 05.00.00 ТЕХНИЧЕСКИЕ НАУКИ
Библиографическая ссылка на статью:
Теленик С.Ф., Романюк Д.І. Використання методу прямого перекладу в системі автоматизованого перекладача // Современные научные исследования и инновации. 2013. № 5 [Электронный ресурс]. URL: https://web.snauka.ru/issues/2013/05/24206 (дата обращения: 31.07.2026).
В умовах бурхливого технічного прогресу, значна частина інформації перейшла з паперового в електронний вигляд. Так її простіше зберігати, передавати та використовувати. Це стосується і літератури, як художньої, так і наукової. За кордоном створюється велика кількість статей, журналів і т. ін., зрозуміти зміст яких людині, без знання відповідної мови, просто неможливо.
Метою цієї системи було створення швидкого перекладу різноманітних текстів, в першу чергу, технічної спрямованості, з німецької мови на українську, з можливістю подальшого її розширення іншими мовами.
В якості метода перекладу було обрано прямий метод перекладу. При прямому перекладі обидва речення (і те, що перекладається, і перекладене) мають одну й ту ж структуру та порядок слів. Дослівний переклад не являється повним та найбільш точним, але він розкриває зміст кожного речення і допомагає перекладачу правильно та швидко зрозуміти його суть.
Крім того, системи, що використовують метод прямого перекладу, мають свої переваги:
– відносна простота;
– висока швидкість роботи;
– невибагливість до системних ресурсів.
На даний момент яскравих представників систем дослівного перекладу на ринку немає, тому в даному випадку зручніше створювати нову систему під конкретну задачу.
Система складається з двох основних частин: електронний словник та автоматизований електронний перекладач, та однієї допоміжної частини для підтримки та різноманітних налаштувань.
Кожне введене слово зберігається у спеціальний файл – базу даних, з якою система працює надалі. В якості бази даних для системи обрано SQLite. Вона має багато переваг над своїми аналогами: простота використання, відсутність необхідності налаштування сервера керування базою даних, відкрита ліцензія, кросплатформенність, безпека та ін.
Розроблена база даних містить наступні таблиці:
– languages – таблиця з мовами, що використовуються;
– knowledges – таблиця галузей
– groups та students – таблиці груп та студентів, що заповнюють базу даних;
– partsOfSpeech – таблиця частин мови;
– words – таблиця слів;
– wordForms – таблиця, в якій містяться всі форм, в яких може перебувати слово що перекладається;
– wordFormsTableStruct – службова таблиця, що містить структуру форм слів для кожної частини мови;
– translations – таблиця перекладених слів;
– links – таблиця зв’язків між словами з різних мов.
Зв’язки між цими таблицями зображено на рисунку 1.
Для перекладу окремого слова з однієї мови на іншу використовується наступний запит до бази даних:
select R.name,K.name
from (
select T.name, KN_ID from translations as T
join (
links as L
left join (
select distinct W.id,W.knowledge_id AS KN_ID
from words as W
left join
wordForms as F
on W.id=F.word_id
where W.language_id=? AND ? in (W.name,F.name)
) AS WF
on L.word_id=WF.id
) as N
on T.id=N.translation_id
where T.language_id=?
) as R
join
knowledges as K
on K.id=R.KN_ID
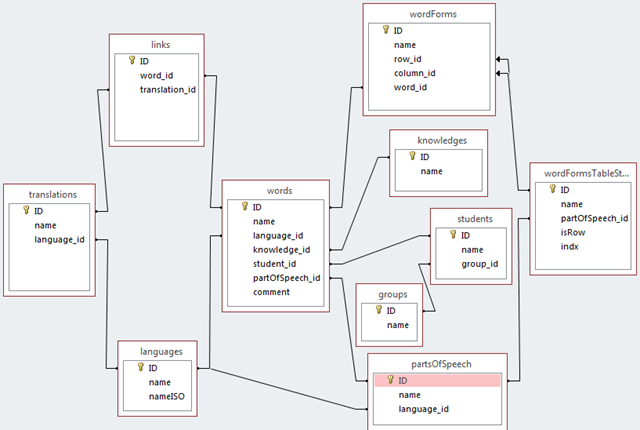
Рисунок 1 – Структура бази даних системи
В якості параметрів до запиту необхідно передати мову, з якої перекладається слово (W.language_id=?), безпосередньо саме слово
(AND ? in (W.name,F.name)), а також мову, в якій потрібно знайти відповідник (T.language_id=?).
Результатом виконання цього запиту буде таблиця, першим стовбцем якої буде переклад шуканого слова в обраній мові, а другим – назва галузі, в якій воно використовується.
Переклад текстів дещо відрізняється від перекладу окремих слів. Розглянемо алгоритм роботи системи під час перекладу тексту:
-
В тексті відбувається пошук розділових знаків, що вказують на кінець речення (крапка, знаки питання та оклику, крапка з комою);
-
Текст розбивається на частини, що знаходяться між знайденими символами – таким чином суцільний текст перетворюється у набір окремих речень;
-
В кожному з отриманих речень відбувається пошук всіх інших розділових знаків (кома, двокрапка, дефіс, тире, лапки, дужки і т. ін.);
-
Аналогічно п.2, кожне речення розбивається на окремі слова, що містяться між знайденими розділовими знаками;
-
Серед знайдених слів відкидаються ті, що не впливають на загальний зміст речення (наприклад, артиклі);
-
З усіх інших слів, що залишилися, формується параметр для основного запиту в базу даних (для кожного речення окремо);
-
Для кожного речення відбувається запит до бази даних з відповідним параметром; результатом цього запиту буде таблиця з варіантами перекладу кожного слова з відповідного речення, що містяться в базі, а також галузь, до якої воно відноситься;
-
В кожному реченні відбувається заміна вихідних слів на їх відповідники з іншої мови,
-
Всі речення об’єднуються в цілісний текст, відповідно до початкового тексту, який видається користувачу для подальшої обробки.
Для перекладу кожного речення з тексту з однієї мови на іншу використовується наступний запит до бази даних:
select wNAME,TRANSLATION,KKK.name as KNOW
from (
((select WT.translation_id as TID,WT.name as wNAME,WT.id as WID
from (
(select id,name
from words
union
select word_id,name
from wordForms) as W
join
links as L
on W.id=L.word_id ) as WT
where ” + words + “
group by WT.translation_id ) as WTL
join
(select id, name as TRANSLATION, language_id as LangOut
from translations
where language_id=” + str_langOut + “) as TR
on WTL.TID=TR.id ) as BLA
join (
select language_id as LangInp, id,knowledge_id as Know
from words
where LangInp=” + str_langIn + “) as WRD
on WRD.id=BLA.WID) AS RES
join
knowledges as KKK
on KKK.id=RES.Know
group by RES.Know,RES.TRANSLATION”
Запит використовує наступні змінні в якості параметрів:
str_langIn – мова, з якої відбується переклад;
str_langOut – мова, в якій потрібно знайти відповідник;
words – спеціальний рядок з усіма словами з речення, що необхідно перекласти. Він формується у циклі наступним чином:
if (!words.Equals(“”))
words += ” OR “;
words += “WT.name LIKE ‘% “+st+”‘ OR WT.name LIKE”+”‘”+st+”‘”,
де st – шукане слово на кожній ітерації циклу.
Після виконання системою перекладу, користувач може вільно обробляти та редагувати отриманий текст з метою покращення якості та подальшого його використання.
Библиографический список
-
Mike Owens. The Definitive Guide to SQLite. – 2 edition. – Apress, 2010. –368 pages.
-
Bell Roger T. Translation and Translating: Theory and Practice / Roger T. Bell. – New-York: Longman, 1991. –298p.
-
Карабан В. Переклад англійської наукової і технічної літератури : Граматичні труднощі, лексичні, термінологічні та жанрово-стилістичні проблеми. –4-е вид., виправлене. – Вінниця: Нова книга, 2004. –574 с.
-
Анисимов В. Компьютерная лингвистика для всех: Мифы. Алгоритмы. Язык. К.: Наукова думка, 1991. – 208 с.
-
Кулагина О. С. Исследования по машинному переводу. - М.: Наука, 1979. – 320 с.
Все статьи автора «Романюк Д.»
© Если вы обнаружили нарушение авторских или смежных прав, пожалуйста, незамедлительно сообщите нам об этом по электронной почте.