 View this article in Russian
View this article in RussianIntroduction
The rapid expansion of cloud computing and large-scale web platforms has fundamentally reshaped the architectural principles and performance requirements underlying modern distributed systems. As organizations increasingly rely on high-load services to support mission-critical operations, the need for scalable, fault-tolerant and performance-optimized architectures becomes a central engineering challenge [1]. The complexity of contemporary digital ecosystems-characterized by heterogeneous workloads, fluctuating traffic patterns, microservices, container orchestration, and globally distributed infrastructures-requires an integrated approach that combines architectural rigor with advanced performance engineering techniques.
Designing high-load cloud and web systems involves not only selecting appropriate architectural paradigms but also ensuring that the system can sustain peak traffic, minimize latency, and maintain predictable behavior under varying operational conditions. Achieving these properties demands a deep understanding of distributed algorithms, resource allocation models, asynchronous communication patterns, observability mechanisms, and autoscaling strategies that align with the system’s functional and non-functional requirements. At the same time, performance optimization in cloud environments is shaped by economic considerations such as cost efficiency, workload elasticity, and the trade-off between compute intensity and operational expenditure.
Given the growing dependence on data-intensive applications, real-time services, and globally accessible platforms, the study of architectural and performance aspects becomes essential for designing reliable high-load systems. This article examines the fundamental architectural considerations, performance optimization strategies, and engineering trade-offs that define the structure and behavior of large-scale cloud and web platforms, highlighting the importance of systematic design principles and continuous performance evaluation.
Architectural principles for high-load cloud and web systems
Designing high-load cloud and web architectures requires adherence to a set of foundational principles that ensure scalability, resilience, operational predictability, and maintainability under intensive workloads [2]. Modern distributed platforms operate in environments characterized by variable traffic intensity, heterogeneous service interactions, and continuous deployment cycles, making architectural discipline a prerequisite for system stability. Central to these principles is the decomposition of monolithic logic into modular, loosely coupled services, enabling independent scaling and failure isolation. Equally important is the use of asynchronous communication patterns, distributed data management strategies, and mechanisms that support horizontal elasticity in response to fluctuating user demand [3].
A critical aspect of architectural design lies in the alignment between system topology and workload characteristics. Stateless compute layers, distributed cache hierarchies, massively parallel request processing, and the strategic placement of data replicas all contribute to maintaining system responsiveness during peak operational loads [4]. Cloud-native infrastructures further reinforce these principles through container orchestration, dynamic provisioning, and managed services capable of autonomous failover and recovery. Table 1 summarizes the core architectural paradigms and their practical implications for high-load system design.
Table 1. Core architectural paradigms for high-load cloud and web systems
|
Architectural paradigm |
Key characteristics |
Impact on high-load performance |
|
Microservices architecture |
Service decomposition, loose coupling, independent deployments |
Improves scalability and fault isolation; enables independent scaling |
|
Event-driven architecture |
Asynchronous communication, message queues, event brokers |
Handles load bursts effectively; increases elasticity |
|
Serverless / function-as-a-service |
Stateless execution, automatic scaling, pay-per-use |
Provides rapid elasticity; suitable for spiky or unpredictable workloads |
|
CQRS + event sourcing |
Separate read/write models, immutable event logs |
Enhances read scalability; supports high-throughput event processing |
|
Distributed caching layers |
In-memory and hierarchical caching |
Reduces load on databases; lowers response latency |
|
Multi-region and hybrid cloud topologies |
Geo-distribution, redundancy, failover |
Improves global availability; reduces latency for distributed users |
The table demonstrates that each architectural paradigm contributes to high-load performance through distinct mechanisms: microservices improve scalability and fault isolation by enabling independent scaling of bottleneck services; event-driven architectures absorb traffic spikes through asynchronous processing; serverless models provide rapid elasticity for unpredictable workloads; and CQRS with event sourcing enhances read throughput and operational auditability [5]. Distributed caching reduces pressure on primary data stores and lowers response latency, while multi-region and hybrid deployments increase global availability and minimize delays for geographically distributed users. Together, these paradigms form a complementary toolkit that enables the design of scalable, resilient, and economically efficient high-load cloud and web systems.
Performance engineering and bottleneck analysis
Performance engineering in high-load cloud and web systems focuses on identifying, quantifying and mitigating factors that limit throughput, increase latency or reduce operational predictability. As distributed platforms scale horizontally, performance degradation rarely stems from a single resource constraint; instead, it emerges from complex interactions between compute capacity, storage I/O, network bandwidth, concurrent request patterns and service orchestration overheads. Understanding these interactions requires systematic measurement and continuous profiling rather than ad-hoc optimization [6].
A key challenge arises from nonlinear latency behavior under increasing load, where systems initially maintain stable response times but eventually enter saturation zones as queues grow and contention increases. This effect is particularly visible in asynchronous service chains, distributed caches and API gateways. The fig. 1 illustrates a typical latency curve: early improvements due to warm caches and efficient connection pooling are followed by a steady rise in response time once throughput approaches or exceeds the system’s effective capacity. Such behavior highlights the importance of proactive performance engineering practices, including back-pressure mechanisms, circuit breakers, autoscaling based on predictive metrics, and architectural adjustments that reduce critical-path dependencies.
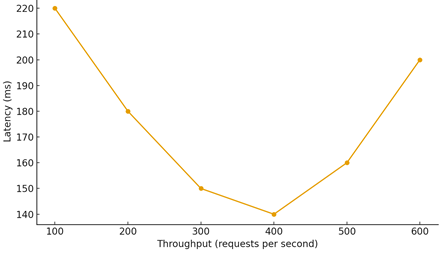
Figure 1. Latency behavior under increasing throughput
Bottleneck analysis must also incorporate economic considerations: optimizing performance in cloud environments is inherently tied to cost models, which require balancing response time targets against compute provisioning strategies. Effective performance engineering therefore integrates load testing, observability, system-level modeling and dynamic tuning to sustain predictable behavior under peak operational conditions.
Scalability models and elasticity mechanisms
Scalability is a foundational property of high-load cloud and web systems, reflecting their ability to maintain predictable performance as demand grows [7]. Two complementary dimensions form the basis of scalability engineering: horizontal expansion, in which additional compute nodes are added to distribute workload, and vertical amplification, which increases the capacity of individual nodes. Modern cloud-native platforms favor horizontal strategies because they support fault isolation, parallel request processing and cost-efficient elasticity.
A well-designed system demonstrates near-linear scalability across moderate traffic ranges, although real-world scalability curves eventually diverge from ideal behavior due to coordination overhead, inter-service communication delays and hotspots in shared resources [8]. The fig. 2 illustrates a typical horizontal scalability pattern: throughput rises proportionally as nodes are added, but the rate of improvement gradually decreases as systemic overhead accumulates. This effect highlights the necessity of architectural techniques such as sharding, load-aware request routing, local caching and minimizing cross-node communication on the critical path.
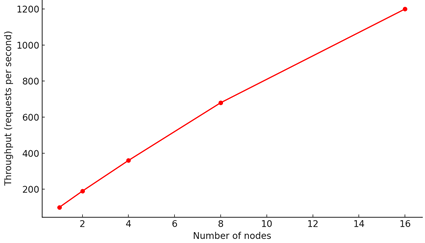
Figure 2. Scalability behavior under horizontal expansion
Elasticity mechanisms extend scalability by enabling systems to adjust capacity dynamically in response to real-time workloads. Reactive autoscaling responds to observed metrics such as CPU utilization or queue length, while predictive autoscaling relies on time-series modeling and anomaly detection to anticipate future demand [9]. Both approaches depend on accurate observability signals and stable scaling policies to avoid oscillation, overprovisioning or delayed response to load bursts. The interplay between scalability and elasticity defines the system’s ability to meet service-level objectives under varying operational conditions.
Conclusion
The analysis of architectural and performance considerations in high-load cloud and web systems demonstrates that system reliability and efficiency depend on a coherent integration of scalable design principles, workload-aware resource allocation and robust operational models. Architectural paradigms such as microservices, event-driven communication and distributed caching provide the structural basis for reducing contention, improving parallelism and isolating failures, enabling systems to maintain predictable behavior under increasing load. The scalability patterns observed in the study further confirm that horizontal expansion is effective only when supported by architectural decisions that minimize coordination overhead and dependency chains.
Performance engineering plays a central role in sustaining high throughput and low latency. The latency and scalability curves examined illustrate that distributed systems exhibit nonlinear performance characteristics, with bottlenecks arising from queuing delays, network saturation and shared resource contention. These findings underscore the need for continuous performance monitoring, meaningful observability metrics and data-driven optimization strategies. Elasticity mechanisms, including both reactive and predictive autoscaling, further enhance system adaptability by ensuring dynamic resource alignment with real-time demand, thereby preventing the degradation that typically accompanies load spikes.
Overall, the study highlights that designing high-load cloud and web systems requires a holistic engineering approach that spans architectural planning, performance modeling and operational governance. The integration of well-founded architectural paradigms with rigorous performance practices allows organizations to build platforms capable of sustaining global-scale workloads while maintaining service-level guarantees. As cloud ecosystems continue to evolve, future advancements will likely focus on greater automation of performance tuning, more resilient distributed protocols and improved cost-performance optimization, all of which are essential for the next generation of high-load digital infrastructure.
References
-
Khriji S., Benbelgacem Y., Chéour R., Houssaini D.E., Kanoun O. Design and implementation of a cloud-based event-driven architecture for real-time data processing in wireless sensor networks // The Journal of Supercomputing. 2022. Vol. 78. № 3. P. 3374-3401.
-
Chen F., Liang H., Li S., Yue L., Xu G. Design of domestic chip scheduling architecture for smart grid based on edge collaboration // 2025 6th International Conference on Electronic Communication and Artificial Intelligence (ICECAI). IEEE. 2025. P. 666-670.
-
Maksimov V. Yu. Startup Latency Analysis in Java Frameworks for Serverless AWS Lambda Deployments // The American Journal of Engineering and Technology. 2025. Vol. 7. № 04. P. 16-21. https://doi.org/10.37547/tajet/Volume07Issue04-03
-
Smirnov A. Modern methods of backend system performance optimization: algorithmic, architectural, and infrastructural aspects // International Journal of Advanced Research in Science, Communication and Technology. 2025. Vol. 5(3). P. 262-266.
-
Rakhmatullayev O. Modern software development methods for high-load systems // Professional Bulletin: Information Technology and Security. 2024. № 1/2024. P. 20-23.
-
Bogutskii A. Engineering approaches to building high-performance real-time services: the case of antifraud services // International Journal of Engineering in Computer Science. 2025. Vol. 7(2). P. 176-179. https://doi.org/10.33545/26633582.2025.v7.i2b.214
-
Yakovenko V., Ulianovska Y., Yakovenko T. Analysing features of e-commerce systems architecture // Technology audit and production reserves. 2022. Vol. 1. № 4. P. 63.
-
Yang H., Zhang W. Design and Implementation of Elastic Architecture for Big Data Information System Based on Cloud Computing [J] // Academic Journal of Computing & Information Science. 2025. Vol. 8. № 1. P. 80-86.
-
Bogdanov S. Development of efficient algorithms for stream data processing in IoT // Professional Bulletin: Information Technology and Security. 2024. № 4/2024. P. 21-26.