В современном обществе использование речевых технологий в качестве альтернативного средства взаимодействия между человеком и различными электронными устройствами уже не является чем-то необычным. Речевые средства взаимодействия дают возможность разрабатывать более дружественные пользовательские интерфейсы, а также максимально миниатюризировать современные средства связи и управления.
С момента появления первых компьютеров ученые работают над решением проблемы автоматического распознавания речи. За эти годы были разработаны различные методы распознавания, созданы работоспособные системы для английского, китайского и целого ряда европейских языков, дающие достаточно высокий процент распознавания. Однако в настоящее время не существует коммерчески успешных систем для распознавания слитной русской речи.
С целью стимулирования исследований в области речевых технологий в России и СНГ международной компанией «Центр речевых технологий» и Санкт-Петербургским национальным исследовательским университетом информационных технологий, механики и оптики в 2013 г. был объявлен конкурс «Родная речь – 2013» с главным призом в сто тысяч рублей. Задача конкурсантов заключалась в разработке прототипа системы распознавания слитной русской речи за один месяц. Подобные конкурсы еще больше подчеркивают важность исследований в этом направлении.
Большинство известных методов распознавания слитной русской речи основаны на применении акустических и языковых моделей в распознавании фраз и отдельных участков речи, в то время как цифровая (битовая) составляющая сигнала остается без внимания. Звук в цифровом виде представляет собой некоторую последовательность нулей и единиц, или битов, проанализировав которую можно составить аналитические выражения и математическую модель для его распознавания. Так в любом звуковом файле T можно выделить: минимальный Tmin и максимальный Tmax элементы, наиболее часто встречающийся элемент Tч, среднее значение Tср элементов последовательности и т. д.
При цифровом анализе записей отдельных букв также возникает ряд проблем. Во-первых, необходимо согласовать распределение битов со скоростью произнесения той или иной буквы, т. е. перед проведением анализа файлов необходимо нормировать их по скорости, либо выявлять закономерности в очередности следования битов, независящие от скорости произнесения звуков. Второй проблемой является влияние эмоциональной окраски на цифровой состав файла. Очевидно, что записи одних и тех же звуков, произнесенных под влиянием разных эмоций, будут иметь различный битовый состав. Таким образом, предстоит вычленить отдельные биты или последовательности битов, которые не зависят от эмоциональной окраски речи. Кроме того, нужно учитывать наличие индивидуальных особенностей речи каждого диктора [1, 2].
В связи с вышесказанным, предлагается следующий способ распознавания гласных букв в слитной русской речи, который основан на использовании возможностей многомерного нечеткого интервально-логического регулятора, разработанного автором, принцип работы которого приведен в статьях [3, 4].
Схема системы распознавания речи приведена на рис. 1.
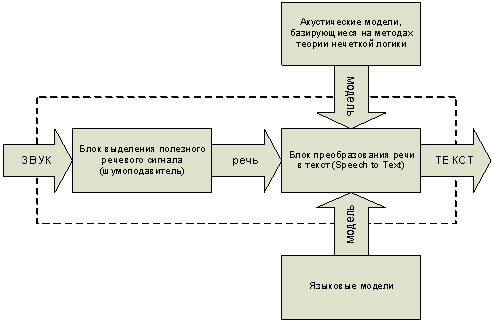
Рисунок 1 – Схема системы распознавания речи
Для подготовки файлов, содержащих гласные звуки, предлагается проведение следующего эксперимента.
В помещении с допустимым уровнем шума и стандартной акустикой производится запись гласных звуков русского языка, произносимых несколькими дикторами. Каждый гласный звук произносится диктором несколько раз, при этом варьируется скорость произнесения, громкость и эмоциональная окраска. Таким образом, создается банк записей, которые предстоит проанализировать с помощью разрабатываемой программы. По результатам анализа полученные последовательности битов сравниваются между собой и выводится некий усредненный цифровой код каждого гласного звука.
Порядок анализа файла, содержащего звуковой фрагмент, имеет вид:
1. Производим интервализацию файла, то есть делим файл на n равных частей, отсекая оставшиеся байты с начала и конца файла, в предположении, что данные байты содержат шум.
Алгоритм интервализации файлов следующий:
а) получаем количество интервалов разбивки n;
б) разбиваем файл на n равных частей. В случае, если размер файла в байтах не делится нацело на n, находим число байт, которые требуется отсечь, это остаток от деления на n. Например, если размер файла – 75 байт, а число интервалов – 7, то остаток от деления равен 5. Далее делим полученный остаток на 2, частное будет равным 2, остаток 1. Тогда
Начало файла = частное + остаток + 1,
Конец файла = размер файла – частное.
Затем разбиваем усеченный файл на n частей.
2. Производим различные методы анализа [5, 6]. Так автором предлагается следующий метод интерпретации файлов, содержащих звуки, в виде последовательности байтов:
– внутри каждого интервала разбивки находим наиболее часто встречающийся байт;
– представляем звук в виде последовательности этих байтов;
– на основании ряда экспериментов находим в каких диапазонах лежат байты внутри каждого интервала для каждого звука, представляющего определенную букву русского алфавита.
Схема интервализации звукового файла представлена на рис. 2, где m – размер звукового файла в байтах; T (1), T (2), …, T (n) – n интервалов разбивки; Tч(1), Tч(2), …, Tч(n) – наиболее часто встречающиеся байты внутри интервалов разбивки T (1), T (2), …, T (n); Tч и Tч‘ – наиболее часто встречающиеся байты в звуковом файле и в последовательности Tч(1), Tч(2), …, Tч(n) соответственно.
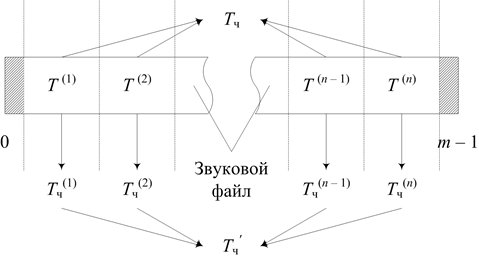
Рисунок 2 – Схема интервализации звукового файла в многомерном интервально-логическом регуляторе
На рисунке 3 представлено окно программного обеспечения для анализа звуковых файлов, разработанного автором.
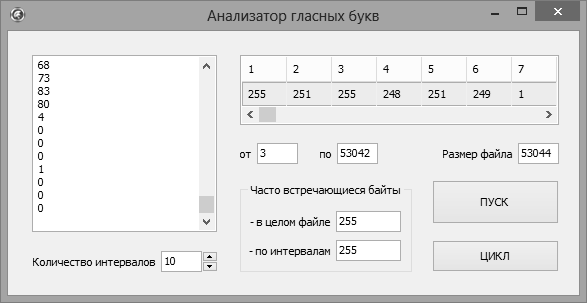
Рисунок 3 – Скриншот системы для анализа звуковых файлов
На данном этапе разработки анализатор гласных букв позволяет варьировать количество интервалов разбивки, выявлять часто встречающиеся байты как в целом файле, так и в каждом отдельном интервале, и получать цифровой код звука в виде последовательности байтов, согласно установленному числу интервалов. На следующем этапе предполагается реализовать механизм сравнения цифровых кодов одного и того же гласного звука, полученных в результате анализа записей разных дикторов.
В результате эксперимента гласный звук “а”, записанный одним диктором 10 раз, но c разной скоростью произнесения и эмоциональной окраской, и разбитый на 10 интервалов имеет коды, приведенные в табл. 1.
Таблица 1 – Цифровые коды гласного звука “а”
| № |
Наиболее часто встречающиеся байты внутри интервалов разбивки (код звука) |
|||||||||
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
| 1 |
255 |
249 |
248 |
251 |
251 |
250 |
254 |
253 |
255 |
32 |
| 2 |
0 |
251 |
251 |
250 |
252 |
251 |
255 |
0 |
255 |
32 |
| 3 |
82 |
0 |
251 |
250 |
252 |
252 |
251 |
251 |
255 |
255 |
| 4 |
0 |
252 |
249 |
252 |
252 |
0 |
255 |
255 |
255 |
32 |
| 5 |
0 |
252 |
253 |
251 |
251 |
251 |
0 |
255 |
255 |
32 |
| 6 |
255 |
254 |
253 |
253 |
254 |
254 |
254 |
254 |
255 |
32 |
| 7 |
82 |
255 |
253 |
252 |
248 |
249 |
251 |
255 |
1 |
255 |
| 8 |
82 |
0 |
250 |
5 |
243 |
248 |
248 |
250 |
0 |
255 |
| 9 |
255 |
251 |
251 |
250 |
251 |
251 |
251 |
0 |
255 |
32 |
| 10 |
255 |
251 |
255 |
248 |
251 |
249 |
1 |
0 |
255 |
32 |
Из таблицы 1 видно, что байты гласного звука “а” внутри десятого интервала разбивки принимают всего два значения – 32 и 255; внутри третьего и пятого интервалов лежат в диапазоне значений [248; 255] и [243; 254] соответственно. Значения внутри остальных интервалов колеблются в диапазоне значений целого байта.
Это говорит о том, что необходим более детальный анализ цифровой структуры файлов с увеличением числа интервалов разбивки, как в целом файле, так и внутри отдельных интервалов. Так для описанного выше эксперимента необходима разбивка третьего и пятого интервалов с целью выявления более точных диапазонов значений байтов или для их подтверждения.
Таблицы, полученные в ходе экспериментов, в перспективе позволят получить цифровые коды гласных звуков для русского языка в виде последовательности байтов (или битов).
Библиографический список
- Антипин А.Ф., Шишкина А.Ф. Об одном пути решения проблемы автоматического распознавания речи // Информационные технологии. Радиоэлектроника. Телекоммуникации. 2012. № 2. Т. 1. С. 48–53.
- Шишкина А.Ф., Антипин А.Ф. Способ цифрового анализа гласных звуков русского языка // Информационные технологии. Радиоэлектроника. Телекоммуникации. 2013. № 3. С. 369–372.
- Антипин А.Ф. Особенности программной реализации многомерных логических регуляторов с переменными в виде совокупности аргументов двузначной логики // Автоматизация и современные технологии. 2014. № 2. С. 30–36.
- Антипин А.Ф. О повышении быстродействия систем интеллектуального управления на базе нечеткой логики // Автоматизация, телемеханизация и связь в нефтяной промышленности. 2013. № 5. С. 22–26.
- Антипин А.Ф. Способ фаззификации значений непрерывных величин с предсказанием термов в многомерном четком логическом регуляторе // Автоматизация в промышленности. 2013. № 9. С. 65–68.
- Степашина Е.В., Мустафина Е.А. Численный алгоритм уточнения механизма химической реакции DRGEP-методом // Журнал Средневолжского математического общества. 2011. Т. 12. № 3. С. 122.