Инструментальные средства разработки учебного контента отстают в развитии от систем дистанционного обучения (СДО) [11]. В свою очередь, успешность применения СДО зависит от качества и эффективной организации учебного контента.
Существующие в настоящее время СДО Moodle, Ilias, Claroline, Atutor и др. не предоставляют разработчикам дистанционных учебных курсов возможность оценки качества учебного контента. Между тем, оценка учебного контента направлена на выявление достоинств и недостатков учебной информации и на принятие решения о необходимости и оптимальных условиях его использования в процессе дистанционного обучения. Одним из направлений решения задачи оценки качества учебного контента систем дистанционного обучения является использование методов квантитативной лингвистики.
Квантитативная лингвистика (quantitative linguistics) – одно из направлений прикладной лингвистики, которое занимается изучением языка с помощью статистических методов [8]. Преимуществом квантитативных методов изучения текстов является их точность и однозначность результатов. Расчет квантитативных характеристик текста необходим для решения следующих проблем:
- определение стилевых и жанровых характеристик текстов, с целью последующей их классификации [7] ;
- изучение образцов текстов, c целью установление авторства [5];
- обучение языку специальности [6, 2].
Разработка учебного контента СДО включает в себя развитие технологий проектирования контента, таких как квантование учебной информации. Квантование - это разделение учебной информации на элементарные фрагменты (учебные единицы, шаги, кадры) различного назначения (информационные, тренирующие [1], контролирующие, управляющие). Одной из проблем технологии проектирования контента является формирование системы количественных критериев для оценки качества квантования учебной информации [9]. Квантитативные характеристики текста могут составлять основу данной системы критериев. Wiio O.A. [13] предложил использовать квантитативные характеристики для оценки показателя сложности: чем больше прилагательных и наречий в тексте, тем сложнее текст. Глагол – самая живая часть речи. Частое применение глаголов в спрягаемых формах приводит к тому, что предложения легко запоминаются и понимаются. В таких предложениях связанные слова находятся близко друг к другу и их связи легко осознаются. Глаголы способствуют пониманию текста [12].
Актуальной является задача автоматизированного подсчета значений квантитативных характеристик текста. Программная реализация автоматизированного определения ряда квантитативных характеристик текста возможна на основе библиотеки морфологического анализа phpMorphy, реализованной на платформе PHP. Библиотека phpMorphy направлена на решение следующих задач [3]:
- лемматизация (получение нормальной формы слова);
- получение всех форм слова;
- полуграмматической информации для слова (часть речи , падеж, спряжение и т.д.);
- изменение формы слова в соответствии с заданными грамматическими характеристиками;
- изменение формы слова по заданному образцу.
Библиотека phpMorphy поддерживает обработку текста на следующих языках: русский, английский, немецкий. С помощью библиотеки phpMorphy могут быть подсчитаны следующие низкоуровневые квантитативные характеристики текста [3]:
- Индекс аналитичности (analyticity index) – отношение числа служебных слов к общему числу слов в тексте;
- Индекс глагольности (Verb index) – отношение числа глаголов к числу слов в тексте;
- Индекс субстантивности (substantive index) – отношение числа существительных к числу слов в тексте;
- Индекс адъективности (adjective index) – отношение числа прилагательных к числу слов в тексте;
- Индекс местоименности (pronoun index) – отношение числа местоименных слов к числу слов в тексте;
- Индекс автосемантичности (autosemanticity index) – отношение числа значащих слов;
- Индекс незнаменательности (unmomentous words index) – отношение числа незнаменательных слов к числу слов в тексте;
- Индекс именной лексики (nominal lexicon index) – отношение суммы чисел существительных и прилагательных к числу слов в тексте.
Обзначения частей речи в библиотеке phpMorphy представлены в табл. 1.
Таблица 1. Обозначения частей речи в библиотеке phpMorphy
| Константа | Описание |
| PMY_RP_NOUN | существительное |
| PMY_RP_ADJ_FULL | прилагательное |
| PMY_RP_ADJ_SHORT | краткое прилагательное |
| PMY_RP_INFINITIVE | инфинитив |
| PMY_RP_VERB | глагол в личной форме |
| PMY_RP_ADVERB_PARTICIPLE | деепричастие |
| PMY_RP_PARTICIPLE | причастие |
| PMY_RP_PARTICIPLE_SHORT | краткое причастие |
| PMY_RP_NUMERAL | числительное (количественное) |
| PMY_RP_NUMERAL_P | порядковое числительное |
| PMY_RP_PRONOUN | местоимение-существительное |
| PMY_RP_PRONOUN_PREDK | местоимение-предикатив |
| PMY_RP_PRONOUN_P | местоименное прилагательное |
| PMY_RP_ADV | наречие |
| PMY_RP_PREDK | предикатив |
| PMY_RP_PREP | предлог |
| PMY_RP_CONJ | союз |
| PMY_RP_INTERJ | междометие |
| PMY_RP_PARTICLE | частица |
| PMY_RP_INP | вводное слово |
| PMY_RP_PHRASE | фразеологизм |
Низкоуровневые квантитативные характеристики текста могут быть выражены через обозначения частей речи библиотеки phpMorphy следущим образом (COUNT_WORDS – количество слов в тексте):
- Индекс аналитичности:
Analyticity_index=(PMY_RP_PREP + PMY_RP_CONJ +
+ PMY_RP_PARTICLE)/COUNT_WORDS.
- Индекс глагольности:
Verb_index = (PMY_RP_INFINITIVE + PMY_RP_VERB +
+PMY_RP_ADVERB_PARTICIPLE + PMY_RP_PARTICIPLE+PMY_RP_PARTICIPLE_SHORT) / COUNT_WORDS.
- Индекс субстантивности:
Substantive_index = PMY_RP_NOUN / COUNT_WORDS.
- Индекс адъективности:
Adjective_index = (PMY_RP_ADJ_FULL + PMY_RP_ADJ_SHORT) / COUNT_WORDS.
- Индекс местоименности:
Pronoun_index = (PMY_RP_PRONOUN + PMY_RP_PRONOUN_PREDK +
+ PMY_RP_PRONOUN_P)/ COUNT_WORDS.
- Индекс автосемантичности:
Autosemanticity_index = (COUNT_WORDS – (PMY_RP_PREP +
+ PMY_RP_CONJ+PMY_RP_PARTICLE) -
- (PMY_RP_PRONOUN + PMY_RP_PRONOUN_PREDK+
+ PMY_RP_PRONOUN_P)) / COUNT_WORDS.
- Индекс незнаменательности:
Unmomentous_words_index = ((PMY_RP_PREP + PMY_RP_CONJ + PMY_RP_PARTICLE ) +
+ (PMY_RP_PRONOUN + PMY_RP_PRONOUN_PREDK +
+ PMY_RP_PRONOUN_P)) / COUNT_WORDS.
- Индекс именной лексики:
Nominal_lexicon_index =(PMY_RP_NOUN + PMY_RP_ADJ_FULL + PMY_RP_ADJ_SHORT)/ COUNT_WORDS.
При использовании библиотеки phpMorphy возможна ситуация, когда для словоформы функция определия части речи возвращает массив с несколькими значениями:
var_dump($morphy->getPartOfSpeech(‘ДУША’));
// array(‘СУЩЕСТВИТЕЛЬНОЕ’, ‘ДЕЕПРИЧАСТИЕ’)
// ДУША образовывается от ДУШ, ДУША и ДУШИТЬ
Поэтому одним из дескрипторов процесса расчета квантитативных характеристик, является степень однозначного определения частей речи.
На основе библиотеки phpMorphy был разработан программный модуль автоматизированного определения представленных выше квантитативных характеристик текста. С использованием данного программного модуля была проведена оценка соответствующих квантитативных параметров для исходного и квантованного текста на примере произведения А.П. Чехова “Белобородый” [4]. Степень однозначного определения частей речи для исходного текста – 69.287, для квантованного текста – 69.263. Результаты анализа исходного и квантованного текстов приведены в табл. 2. Результаты анализа соответствующих фрагментов исходного и квантованного текстов приведены в табл. 3-4.
Таблица 2. Квантитативные характеристики текста
|
Анализируемый текст |
Количество |
Индекс |
Индекс глаголь-ности |
Индекс субстантив-ности |
Индекс адъектив-ности |
Индекс местои-менности |
Индекс автосеман-тичности |
Индекс незнаме-нательности |
Индекс именной лексики |
| Исходный текст |
1512 |
0.215 |
0.214 |
0.255 |
0.080 |
0.106 |
0.891 |
0.321 |
0.334 |
| Квантованный текст |
719 |
0.219 |
0.207 |
0.258 |
0.077 |
0.106 |
0.887 |
0.326 |
0.335 |
Таблица 3. Квантитативные характеристики фрагментов исходного текста
|
Фрагмент исходного текста |
Количество |
Индекс |
Индекс глаголь-ности |
Индекс субстантив-ности |
Индекс адъектив-ности |
Индекс местои-менности |
Индекс автосеман-тичности |
Индекс незнаме-нательности |
Индекс именной лексики |
| Фрагмент №1 |
189 |
0.231 |
0.194 |
0.245 |
0.103 |
0.093 |
0.863 |
0.324 |
0.348 |
| Фрагмент №2 |
207 |
0.191 |
0.188 |
0.254 |
0.085 |
0.132 |
0.941 |
0.323 |
0.339 |
| Фрагмент №3 |
139 |
0.205 |
0.225 |
0.313 |
0.095 |
0.042 |
0.837 |
0.247 |
0.408 |
| Фрагмент №4 |
170 |
0.267 |
0.201 |
0.209 |
0.073 |
0.143 |
0.846 |
0.410 |
0.281 |
| Фрагмент №5 |
143 |
0.183 |
0.207 |
0.228 |
0.1 |
0.139 |
0.956 |
0.322 |
0.329 |
| Фрагмент №6 |
268 |
0.213 |
0.248 |
0.254 |
0.041 |
0.110 |
0.897 |
0.323 |
0.294 |
| Фрагмент №7 |
396 |
0.213 |
0.217 |
0.269 |
0.082 |
0.090 |
0.878 |
0.303 |
0.351 |
Таблица 4. Квантитативные характеристики фрагментов квантованного текста
|
Фрагмент квантованного текста |
Количество |
Индекс |
Индекс глаголь-ности |
Индекс субстантив-ности |
Индекс адъектив-ности |
Индекс местои-менности |
Индекс автосеман-тичности |
Индекс незнаме-нательности |
Индекс именной лексики |
| Фрагмент №1 |
59 |
67.797 |
0.161 |
0.246 |
0.285 |
0.124 |
0.079 |
0.918 |
0.240 |
| Фрагмент №2 |
118 |
62.712 |
0.206 |
0.171 |
0.263 |
0.061 |
0.126 |
0.919 |
0.332 |
| Фрагмент №3 |
63 |
74.603 |
0.222 |
0.238 |
0.307 |
0.079 |
0.032 |
0.810 |
0.254 |
| Фрагмент №4 |
80 |
65.000 |
0.295 |
0.172 |
0.210 |
0.078 |
0.135 |
0.841 |
0.430 |
| Фрагмент №5 |
108 |
66.660 |
0.168 |
0.216 |
0.228 |
0.122 |
0.147 |
0.978 |
0.315 |
| Фрагмент №6 |
60 |
78.300 |
0.250 |
0.195 |
0.292 |
0.022 |
0.108 |
0.858 |
0.358 |
| Фрагмент №7 |
231 |
70.562 |
0.230 |
0.219 |
0.255 |
0.066 |
0.094 |
0.864 |
0.324 |
Проанализируем, как изменилась сложность квантованного текста по сравнению с исходным. Для количественной оценки сложности текста используем формулу Ю.Тулдава [11]:
R(i,j)=i*lg(j), (1)
где R(i,j)– индекс сложности текста (рис.1), i – средняя длина слова в слогах, j – средняя длина предложений в словах. Формула (1) разработана на основе закономерности, наблюдаемой в разных языках. Поэтому формула Ю. Тулдава предназначена для анализа текста на разных языках.

Рис. 1. Вид функции R(i,j)
В табл. 5 приведены значения индекса сложности текста для соответствующих фрагментов исходного и квантованного текста.
Таблица 5. Индекс сложности текста R(i,j)
|
Фрагмент исходного текста |
Исходный текст |
Квантованный текст |
|
Фрагмент №1 |
3.016 |
2.44 |
|
Фрагмент №2 |
2.542 |
2.509 |
|
Фрагмент №3 |
2.635 |
3.323 |
|
Фрагмент №4 |
2.853 |
2.453 |
|
Фрагмент №5 |
2.805 |
2.243 |
|
Фрагмент №6 |
2.587 |
2.264 |
|
Фрагмент №7 |
2.113 |
2.109 |
Индекс сложности R (i,j) для квантованного текста равен 2.353, а для исходного текста равен 2.508, что свидетельствует о лучшем представлении квантованного текста. В тоже время, сравнительный анализ индексов сложности для исходного и квантованного текстов по фрагментам (рис. 2) позволил определить фрагменты квантованного текста №2, №3 и №7, как требующие дальнейшего преобразования.
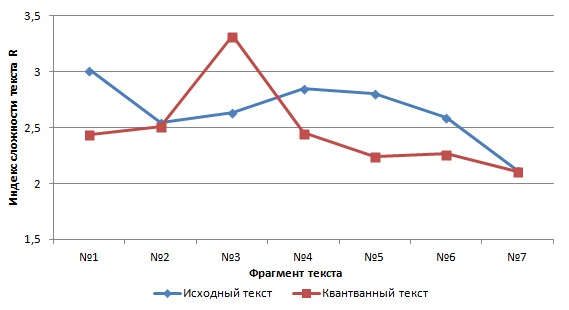 Рис. 2. Сравнительный анализ индекса сложности текста по фрагментам
Рис. 2. Сравнительный анализ индекса сложности текста по фрагментам
Библиотека phpMorphy позволяет автоматизировать процесс получения квантитативных характеристик текстов и рекомендуется к использованию в web-информационных системах, ориентированных на решение задач квантитативной лингвистики.
Библиографический список
- Абрамова О.Ф. Особенности формирования банка тестовых заданий по специальным техническим дисциплинам для программной реализации системы адаптивного тестирования // Современная техника и технологии. 2013. № 11 (27). С. 2.
- Агеев В.В., Сергевнина В.М., Яковлева Е.И. Cредства оптимизации лингводидактики для сокращенных форм обучения // Вестник Нижегородского университета им. Н.И. Лобачевского. 2011. № 3-1. С. 37-43.
- Библиотека phpMorphy. URL: http://phpmorphy.sourceforge.net.
- Веренчик И. Квантование текста и разработка заданий в тестовой форме (на примере произведений А.П. Чехова) // Педагогические измерения. 2012. № 1. С. 98-105.
- Верхозин С.С. К вопросу о лингвотеоретических основах методик авторизации текста // Ученые записки Забайкальского государственного университета. Серия: Филология, история, востоковедение. 2013. № 2 (49). С. 22-27.
- Дудиков М.Ю. Квантитативные характеристики профессиональной коммуникации // Вестник Челябинского государственного университета. 2009. № 35. С. 63-67.
- Журавлев А.Ф. Опыт квантитативно-типологического исследования разновидностей устной речи // Разновидности городской устной речи. Сборник научных трудов. – М.: Наука, 1988. С. 84-150.
- Кащеева А.В. Квантитативные и качественные методы исследования в прикладной лингвистике // Социально-экономические явления и процессы. 2013. № 3 (049). С. 155-162.
- Рыбанов А.А. Количественные метрики для оценки качества квантования учебной информации // Педагогические измерения. 2013. № 4. С. 3-12.
- Рыбанов А.А. Оценка качества текстов электронных средств обучения // Школьные технологии. 2011. № 6. С. 172-174.
- Тулдава Ю.А. Об измерении трудности текста. – Ученые записки Тартуского государственного университета, 1975, вып. 345. С. 102-119.
- Flesh R. The Art of Plain Talk.- New York: Haper and Brothers Publisher, 1946. – 210 p.
- Wiio O.A. Readability. Compression and Readership. Acta Universitatis Tamperensis, 1968, vol. 22 (A), p. 161.