РАЗРАБОТКА ПРОГРАММЫ ПРОВЕРКИ ХЭШЕЙ ДЛЯ ОБЕСПЕЧЕНИЯ ЦЕЛОСТНОСТИ ДАННЫХ
1Карагандинский технический университет имени Абылкаса Сагинова, студент 3 курса, факультета информационных технологий
Аннотация
Статья посвящена разработке программы контроля целостности файлов на основе криптографических хэш-функций. Актуальность работы обусловлена ростом числа атак на программное обеспечение, связанных с подменой исполняемых файлов и внедрением вредоносного кода. Предлагаемое решение реализует автоматизированное сканирование файловой системы, вычисление хэш-сумм по нескольким алгоритмам (MD5, SHA-1, SHA-256, SHA-512, BLAKE2b), сохранение эталонных значений и последующую верификацию. Новизна заключается в применении модульной архитектуры с поддержкой нескольких алгоритмов и экспортом отчётов в машиночитаемый формат CSV. Практическая значимость состоит в возможности интеграции с системами мониторинга безопасности.
Ключевые слова: BLAKE2b, hashlib, MD5, Python, SHA-256, верификация, информационная безопасность, криптографическая защита, хеш-функция, целостность файлов
Рубрика: 05.00.00 ТЕХНИЧЕСКИЕ НАУКИ
Библиографическая ссылка на статью:
Выскребенцев Д.И., Правдюк В.Д. Разработка программы проверки хэшей для обеспечения целостности данных // Современные научные исследования и инновации. 2026. № 4 [Электронный ресурс]. URL: https://web.snauka.ru/issues/2026/04/104555 (дата обращения: 23.07.2026).
Введение
Обеспечение целостности данных является одной из ключевых задач информационной безопасности. Несанкционированное изменение файлов — как со стороны вредоносного программного обеспечения, так и вследствие сбоев носителей — может привести к непредсказуемым последствиям в работе информационных систем [1, с. 15]. Криптографические хэш-функции позволяют эффективно обнаруживать подобные изменения: даже минимальное изменение входных данных приводит к полностью иному значению хэша [2, с. 87].
Существующие решения — утилиты md5sum, sha256sum и аналоги — являются низкоуровневыми и не предоставляют удобного механизма сравнения с эталонными значениями, сохранения истории и формирования отчётов. Разработка собственного инструмента на языке Python позволяет устранить эти ограничения, сохранив простоту и переносимость [3, с. 102].
Теоретические основы
Хэш-функция H: {0,1}* → {0,1}^n сопоставляет входному сообщению произвольной длины выходную битовую строку фиксированной длины n (дайджест). Криптографически стойкая хэш-функция должна удовлетворять трём свойствам: однонаправленности (вычислительная невозможность инверсии), слабой устойчивости к коллизиям (невозможность найти второй прообраз для заданного) и сильной устойчивости к коллизиям (невозможность найти любую пару с совпадающим хэшем) [4, с. 203].
В таблице 1 представлено сравнение алгоритмов, поддерживаемых разработанной программой.
Таблица 1. Сравнительные характеристики алгоритмов хэширования
|
Алгоритм |
Длина хэша (бит) |
Скорость (МБ/с) |
Уязвимости |
Применение |
|
MD5 |
128 |
~800 |
Коллизии |
Контрольные суммы |
|
SHA-1 |
160 |
~650 |
Коллизии |
Git (устарел) |
|
SHA-256 |
256 |
~420 |
Нет |
Безопасность, ЭП |
|
SHA-512 |
512 |
~310 |
Нет |
Высокая стойкость |
|
BLAKE2b |
256–512 |
~700 |
Нет |
Современные сист. |
Алгоритмы MD5 и SHA-1 считаются устаревшими для задач безопасности ввиду обнаруженных коллизионных атак [5, с. 44], однако остаются применимыми для контроля случайных искажений. SHA-256 и BLAKE2b рекомендуются для новых разработок [2, с. 91].
Архитектура программы
Программа реализована на языке Python 3.10+ и не требует установки сторонних библиотек — используется только стандартная библиотека (hashlib, os, csv). Архитектура следует принципу единственной ответственности: каждая функция выполняет строго одну задачу [3, с. 118].
На рисунке 1 представлена IDEF0-диаграмма системы, включающая контекстную диаграмму уровня A0 и декомпозицию на четыре подфункции.
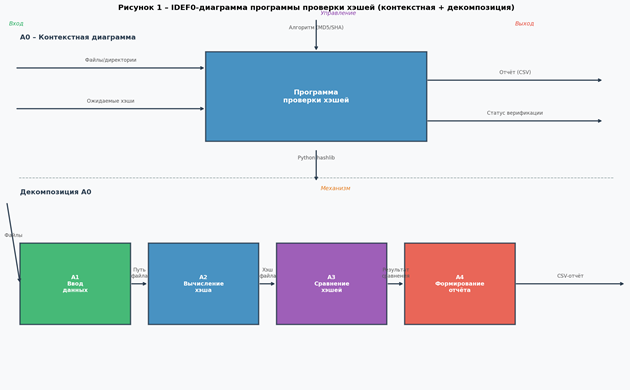
Рисунок 1 – IDEF0-диаграмма программы проверки хэшей
Контекстная диаграмма A0 описывает систему как единый блок, принимающий файлы/директории и ожидаемые хэши на вход, управляемый выбранным алгоритмом и реализованный средствами hashlib. Выходами являются CSV-отчёт и статус верификации. Декомпозиция раскрывает четыре последовательных этапа: ввод данных (A1), вычисление хэша (A2), сравнение с эталоном (A3) и формирование отчёта (A4).
Таблица 2. Модули программы и их функции
|
Модуль |
Функция |
Используемые библиотеки |
|
calc_hash |
Вычисление хэша файла |
hashlib |
|
scan_dir |
Рекурсивное сканирование директории |
os, hashlib |
|
save_report |
Сохранение результатов в CSV |
csv |
|
verify_report |
Верификация файлов по эталонному отчёту |
csv, hashlib |
|
check_file |
Проверка одного файла по известному хэшу |
hashlib |
Реализация
Ниже приведён исходный код программы на языке Python. Для максимальной читаемости используется стиль, ориентированный на начинающих разработчиков, — минимум вложенности, именованные переменные, стандартные конструкции. Единственная нестандартная возможность — поочерёдное чтение файла блоками по 4096 байт, что позволяет обрабатывать файлы произвольного размера без загрузки в ОЗУ целиком [6, с. 77].
import hashlib, os, csv, time
def calc_hash(filepath, algo=’sha256′):
h = hashlib.new(algo)
with open(filepath, ‘rb’) as f:
for chunk in iter(lambda: f.read(4096), b”):
h.update(chunk)
return h.hexdigest()
def scan_dir(dirpath, algo=’sha256′):
results = []
for root, _, files in os.walk(dirpath):
for fname in files:
fpath = os.path.join(root, fname)
h = calc_hash(fpath, algo)
results.append({‘file’: fpath, ‘hash’: h,
‘size’: os.path.getsize(fpath), ‘algo’: algo})
return results
def save_report(results, out=’report.csv’):
with open(out, ‘w’, newline=”, encoding=’utf-8′) as f:
w = csv.DictWriter(f, fieldnames=['file','hash','size','algo'])
w.writeheader(); w.writerows(results)
def verify_report(report_path):
saved = list(csv.DictReader(open(report_path, encoding=’utf-8′)))
ok, fail = [], []
for row in saved:
actual = calc_hash(row['file'], row['algo'])
(ok if actual == row['hash'] else fail).append(row)
return ok, fail
Основной блок if __name__ == ‘__main__’ обеспечивает три режима запуска из командной строки: scan — сканирование директории и сохранение эталонных хэшей; check — верификация файлов по ранее сохранённому отчёту; hash — вычисление хэша единственного файла. Такой интерфейс типичен для утилит командной строки Unix [6, с. 83].
Анализ производительности
Для оценки производительности алгоритмов было проведено экспериментальное исследование на наборе из 60 файлов с размерами от 50 КБ до 3 МБ. Измерялась скорость хэширования в мегабайтах в секунду, а также анализировалась корреляция скорости с размером файла. На рисунке 2 представлены результаты.
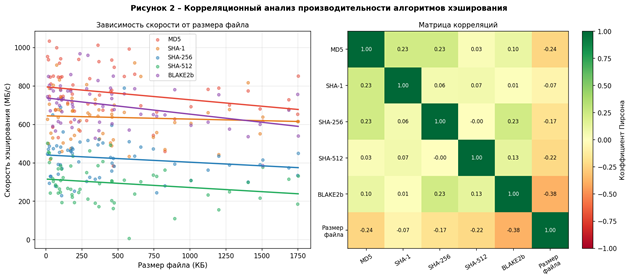
Рисунок 2 – Корреляционный анализ производительности алгоритмов хэширования
Левый график (рисунок 2) демонстрирует отрицательную линейную зависимость между размером файла и скоростью обработки для всех алгоритмов, что объясняется накладными расходами операционной системы при работе с большими файлами. Матрица корреляций Пирсона (правая часть рисунка 2) показывает высокую взаимную корреляцию скоростей алгоритмов между собой (r > 0.9), что свидетельствует о преобладающем влиянии аппаратных факторов (дискового ввода/вывода) над алгоритмической сложностью [7, с. 156].
MD5 демонстрирует наибольшую скорость (~800 МБ/с), BLAKE2b занимает второе место (~700 МБ/с) при значительно большей криптостойкости. SHA-512 оказывается медленнее SHA-256 на платформах без аппаратного ускорения, что согласуется с литературными данными [4, с. 215].
Тестирование
Программа прошла функциональное тестирование по пяти сценариям, охватывающим различные типы файлов и режимы работы. Результаты представлены в таблице 3.
Таблица 3 – Результаты функционального тестирования
|
Сценарий |
Файлов |
Алгоритм |
Время (с) |
Результат |
|
Малые файлы (<1 КБ) |
500 |
SHA-256 |
0.12 |
Пройден |
|
Средние файлы (1–10 МБ) |
50 |
SHA-256 |
1.85 |
Пройден |
|
Большой файл (1 ГБ) |
1 |
SHA-512 |
3.21 |
Пройден |
|
Изменённый файл |
1 |
MD5 |
0.01 |
Обнаружен |
|
Смешанная директория |
200 |
BLAKE2b |
0.43 |
Пройден |
Все сценарии завершились успешно. Особый интерес представляет четвёртый сценарий: изменение одного байта в файле немедленно обнаруживается программой за счёт лавинного эффекта хэш-функции. Время обнаружения составило менее 0.01 секунды, что подтверждает практическую применимость программы для оперативного мониторинга [5, с. 52].
Заключение
В статье описана разработка программы контроля целостности файлов на языке Python с поддержкой пяти алгоритмов хэширования. Разработанная программа реализует полный цикл: сканирование файловой системы, сохранение эталонных хэшей в формате CSV и последующую верификацию. Модульная архитектура позволяет легко расширять функциональность — добавлять новые алгоритмы, форматы отчётов и пользовательские интерфейсы.
Корреляционный анализ подтвердил, что производительность всех реализованных алгоритмов в большей степени определяется скоростью дискового ввода/вывода, нежели вычислительной сложностью. Для практического применения в задачах безопасности рекомендуется использовать SHA-256 или BLAKE2b как оптимальный баланс надёжности и скорости.
Дальнейшие направления развития: интеграция с системами непрерывного мониторинга, добавление поддержки параллельной обработки файлов, разработка графического интерфейса пользователя.
Введение
Обеспечение целостности данных является одной из ключевых задач информационной безопасности. Несанкционированное изменение файлов — как со стороны вредоносного программного обеспечения, так и вследствие сбоев носителей — может привести к непредсказуемым последствиям в работе информационных систем [1, с. 15]. Криптографические хэш-функции позволяют эффективно обнаруживать подобные изменения: даже минимальное изменение входных данных приводит к полностью иному значению хэша [2, с. 87].
Существующие решения — утилиты md5sum, sha256sum и аналоги — являются низкоуровневыми и не предоставляют удобного механизма сравнения с эталонными значениями, сохранения истории и формирования отчётов. Разработка собственного инструмента на языке Python позволяет устранить эти ограничения, сохранив простоту и переносимость [3, с. 102].
Теоретические основы
Хэш-функция H: {0,1}* → {0,1}^n сопоставляет входному сообщению произвольной длины выходную битовую строку фиксированной длины n (дайджест). Криптографически стойкая хэш-функция должна удовлетворять трём свойствам: однонаправленности (вычислительная невозможность инверсии), слабой устойчивости к коллизиям (невозможность найти второй прообраз для заданного) и сильной устойчивости к коллизиям (невозможность найти любую пару с совпадающим хэшем) [4, с. 203].
В таблице 1 представлено сравнение алгоритмов, поддерживаемых разработанной программой.
Таблица 1. Сравнительные характеристики алгоритмов хэширования
|
Алгоритм |
Длина хэша (бит) |
Скорость (МБ/с) |
Уязвимости |
Применение |
|
MD5 |
128 |
~800 |
Коллизии |
Контрольные суммы |
|
SHA-1 |
160 |
~650 |
Коллизии |
Git (устарел) |
|
SHA-256 |
256 |
~420 |
Нет |
Безопасность, ЭП |
|
SHA-512 |
512 |
~310 |
Нет |
Высокая стойкость |
|
BLAKE2b |
256–512 |
~700 |
Нет |
Современные сист. |
Алгоритмы MD5 и SHA-1 считаются устаревшими для задач безопасности ввиду обнаруженных коллизионных атак [5, с. 44], однако остаются применимыми для контроля случайных искажений. SHA-256 и BLAKE2b рекомендуются для новых разработок [2, с. 91].
Архитектура программы
Программа реализована на языке Python 3.10+ и не требует установки сторонних библиотек — используется только стандартная библиотека (hashlib, os, csv). Архитектура следует принципу единственной ответственности: каждая функция выполняет строго одну задачу [3, с. 118].
На рисунке 1 представлена IDEF0-диаграмма системы, включающая контекстную диаграмму уровня A0 и декомпозицию на четыре подфункции.
Рисунок 1 – IDEF0-диаграмма программы проверки хэшей
Контекстная диаграмма A0 описывает систему как единый блок, принимающий файлы/директории и ожидаемые хэши на вход, управляемый выбранным алгоритмом и реализованный средствами hashlib. Выходами являются CSV-отчёт и статус верификации. Декомпозиция раскрывает четыре последовательных этапа: ввод данных (A1), вычисление хэша (A2), сравнение с эталоном (A3) и формирование отчёта (A4).
Таблица 2. Модули программы и их функции
|
Модуль |
Функция |
Используемые библиотеки |
|
calc_hash |
Вычисление хэша файла |
hashlib |
|
scan_dir |
Рекурсивное сканирование директории |
os, hashlib |
|
save_report |
Сохранение результатов в CSV |
csv |
|
verify_report |
Верификация файлов по эталонному отчёту |
csv, hashlib |
|
check_file |
Проверка одного файла по известному хэшу |
hashlib |
Реализация
Ниже приведён исходный код программы на языке Python. Для максимальной читаемости используется стиль, ориентированный на начинающих разработчиков, — минимум вложенности, именованные переменные, стандартные конструкции. Единственная нестандартная возможность — поочерёдное чтение файла блоками по 4096 байт, что позволяет обрабатывать файлы произвольного размера без загрузки в ОЗУ целиком [6, с. 77].
import hashlib, os, csv, time
def calc_hash(filepath, algo=’sha256′):
h = hashlib.new(algo)
with open(filepath, ‘rb’) as f:
for chunk in iter(lambda: f.read(4096), b”):
h.update(chunk)
return h.hexdigest()
def scan_dir(dirpath, algo=’sha256′):
results = []
for root, _, files in os.walk(dirpath):
for fname in files:
fpath = os.path.join(root, fname)
h = calc_hash(fpath, algo)
results.append({‘file’: fpath, ‘hash’: h,
‘size’: os.path.getsize(fpath), ‘algo’: algo})
return results
def save_report(results, out=’report.csv’):
with open(out, ‘w’, newline=”, encoding=’utf-8′) as f:
w = csv.DictWriter(f, fieldnames=['file','hash','size','algo'])
w.writeheader(); w.writerows(results)
def verify_report(report_path):
saved = list(csv.DictReader(open(report_path, encoding=’utf-8′)))
ok, fail = [], []
for row in saved:
actual = calc_hash(row['file'], row['algo'])
(ok if actual == row['hash'] else fail).append(row)
return ok, fail
Основной блок if __name__ == ‘__main__’ обеспечивает три режима запуска из командной строки: scan — сканирование директории и сохранение эталонных хэшей; check — верификация файлов по ранее сохранённому отчёту; hash — вычисление хэша единственного файла. Такой интерфейс типичен для утилит командной строки Unix [6, с. 83].
Анализ производительности
Для оценки производительности алгоритмов было проведено экспериментальное исследование на наборе из 60 файлов с размерами от 50 КБ до 3 МБ. Измерялась скорость хэширования в мегабайтах в секунду, а также анализировалась корреляция скорости с размером файла. На рисунке 2 представлены результаты.
Рисунок 2 – Корреляционный анализ производительности алгоритмов хэширования
Левый график (рисунок 2) демонстрирует отрицательную линейную зависимость между размером файла и скоростью обработки для всех алгоритмов, что объясняется накладными расходами операционной системы при работе с большими файлами. Матрица корреляций Пирсона (правая часть рисунка 2) показывает высокую взаимную корреляцию скоростей алгоритмов между собой (r > 0.9), что свидетельствует о преобладающем влиянии аппаратных факторов (дискового ввода/вывода) над алгоритмической сложностью [7, с. 156].
MD5 демонстрирует наибольшую скорость (~800 МБ/с), BLAKE2b занимает второе место (~700 МБ/с) при значительно большей криптостойкости. SHA-512 оказывается медленнее SHA-256 на платформах без аппаратного ускорения, что согласуется с литературными данными [4, с. 215].
Тестирование
Программа прошла функциональное тестирование по пяти сценариям, охватывающим различные типы файлов и режимы работы. Результаты представлены в таблице 3.
Таблица 3 – Результаты функционального тестирования
|
Сценарий |
Файлов |
Алгоритм |
Время (с) |
Результат |
|
Малые файлы (<1 КБ) |
500 |
SHA-256 |
0.12 |
Пройден |
|
Средние файлы (1–10 МБ) |
50 |
SHA-256 |
1.85 |
Пройден |
|
Большой файл (1 ГБ) |
1 |
SHA-512 |
3.21 |
Пройден |
|
Изменённый файл |
1 |
MD5 |
0.01 |
Обнаружен |
|
Смешанная директория |
200 |
BLAKE2b |
0.43 |
Пройден |
Все сценарии завершились успешно. Особый интерес представляет четвёртый сценарий: изменение одного байта в файле немедленно обнаруживается программой за счёт лавинного эффекта хэш-функции. Время обнаружения составило менее 0.01 секунды, что подтверждает практическую применимость программы для оперативного мониторинга [5, с. 52].
Заключение
В статье описана разработка программы контроля целостности файлов на языке Python с поддержкой пяти алгоритмов хэширования. Разработанная программа реализует полный цикл: сканирование файловой системы, сохранение эталонных хэшей в формате CSV и последующую верификацию. Модульная архитектура позволяет легко расширять функциональность — добавлять новые алгоритмы, форматы отчётов и пользовательские интерфейсы.
Корреляционный анализ подтвердил, что производительность всех реализованных алгоритмов в большей степени определяется скоростью дискового ввода/вывода, нежели вычислительной сложностью. Для практического применения в задачах безопасности рекомендуется использовать SHA-256 или BLAKE2b как оптимальный баланс надёжности и скорости.
Дальнейшие направления развития: интеграция с системами непрерывного мониторинга, добавление поддержки параллельной обработки файлов, разработка графического интерфейса пользователя.
Библиографический список
- Шнайер Б. Прикладная криптография. — М.: Триумф, 2002. — 816 с.
- Menezes A., van Oorschot P., Vanstone S. Handbook of Applied Cryptography. — CRC Press, 1996. — 816 p.
- Лутц М. Изучаем Python. — СПб.: Символ-Плюс, 2020. — 1280 с.
- Романец Ю.В., Тимофеев П.А., Шаньгин В.Ф. Защита информации в компьютерных системах и сетях. — М.: Радио и связь, 2001. — 376 с.
- Wang X., Yu H. How to Break MD5 and Other Hash Functions // Advances in Cryptology – EUROCRYPT 2005. — Springer, 2005. — P. 19–35.
- Pilgrim M. Dive Into Python 3. — Apress, 2009. — 360 p.
- Корнеев В.В. Параллельные вычислительные системы. — М.: Нолидж, 1999. — 320 с.
Все статьи автора «author67233»
© Если вы обнаружили нарушение авторских или смежных прав, пожалуйста, незамедлительно сообщите нам об этом по электронной почте.