ПРАКТИЧЕСКАЯ РЕАЛИЗАЦИЯ СИСТЕМЫ ОБНАРУЖЕНИЯ АТАК СОЦИАЛЬНОЙ ИНЖЕНЕРИИ НА ОСНОВЕ МАШИННОГО ОБУЧЕНИЯ
1Карагандинский технический университет имени Абылкаса Сагинова, студент 3 курса
Аннотация
В статье представлена практическая реализация интеллектуальной системы обнаружения фишинга и атак социальной инженерии. Разработан программный комплекс, включающий модуль машинного обучения на основе логистической регрессии с гибридным признаковым пространством (TF-IDF и инженерные признаки) и веб-интерфейс на базе Gradio. Система обеспечивает многоуровневую оценку угроз, идентификацию конкретных тактик злоумышленников и формирование рекомендаций для пользователя. Приведены детальное описание архитектуры, алгоритмы обработки признаков, схема интерфейса и результаты тестирования.
Ключевые слова: Gradio, Python, TF-IDF, кибербезопасность, классификация текстов., логистическая регрессия, машинное обучение, обнаружение угроз, социальная инженерия, фишинг
Рубрика: 05.00.00 ТЕХНИЧЕСКИЕ НАУКИ
Библиографическая ссылка на статью:
Бобер О.Н., Гарифуллин И.Р., Гутникевич Е.А. Практическая реализация системы обнаружения атак социальной инженерии на основе машинного обучения // Современные научные исследования и инновации. 2026. № 4 [Электронный ресурс]. URL: https://web.snauka.ru/issues/2026/04/104551 (дата обращения: 23.07.2026).
1. ВВЕДЕНИЕ
Предыдущая аналитическая работа [1] установила, что развитие генеративного искусственного интеллекта кардинально изменило ландшафт угроз социальной инженерии: атаки стали высокоперсонализированными, автоматизированными и трудно отличимыми от легитимной коммуникации. Логичным продолжением теоретического анализа является создание практического инструмента противодействия — системы, способной в реальном времени идентифицировать фишинговые сообщения и предупреждать пользователей об угрозах.
Настоящая статья посвящена описанию разработанного авторами программного комплекса «AI-Агент: Детектор фишинга и социальной инженерии». Комплекс реализует многоуровневый анализ текстовых сообщений с применением методов машинного обучения и сигнатурного анализа. Решение ориентировано на практическое применение: конечный пользователь получает не только бинарный вердикт «фишинг / не фишинг», но и детализированную расшифровку признаков угрозы и конкретные рекомендации по действиям.
Цель статьи — детально описать архитектуру системы, алгоритмы обработки данных, принятые технические решения и результаты тестирования, демонстрируя применимость методов машинного обучения для задач кибербезопасности в доступной и воспроизводимой форме.
2. ПОСТАНОВКА ЗАДАЧИ И ТРЕБОВАНИЯ К СИСТЕМЕ
Анализ существующих решений в области обнаружения фишинга показывает, что большинство из них либо требуют корпоративной инфраструктуры, либо функционируют только как плагины к почтовым клиентам. Целевой аудиторией разработанной системы являются рядовые пользователи и сотрудники организаций, получающие подозрительные сообщения по различным каналам: электронная почта, SMS, мессенджеры, социальные сети.
На основании анализа актуальных угроз [1, 2] были сформулированы следующие требования к системе:
-
автономность: возможность работы без подключения к внешним сервисам и облачным API;
-
мультиканальность: анализ любых текстовых сообщений вне зависимости от источника;
-
интерпретируемость: результат анализа должен содержать объяснение, а не только оценку риска;
-
доступность: веб-интерфейс, не требующий установки специализированного программного обеспечения;
-
расширяемость: архитектура должна допускать дообучение модели на новых данных.
Дополнительно было принято решение реализовать четырёхуровневую шкалу риска вместо бинарной классификации, что позволяет пользователю принимать взвешенные решения в пограничных случаях.
3. АРХИТЕКТУРА СИСТЕМЫ
3.1. Общая структура
Система состоит из двух основных модулей: модуля машинного обучения (файл train_model.py) и модуля пользовательского интерфейса (файл app.py). Взаимодействие между ними осуществляется через сериализованный файл модели phishing_model.pkl, создаваемый при первом запуске. Такой подход обеспечивает разделение ответственности и упрощает замену или обновление модели без изменения интерфейса.
Таблица 1. Компоненты системы и их назначение
|
Компонент |
Файл |
Назначение |
| Модуль обучения | train_model.py | Формирование датасета, извлечение признаков, обучение и сохранение модели |
| Модуль анализа | app.py (функция analyze) | Загрузка модели, векторизация входного текста, классификация, формирование вывода |
| Сигнатурный модуль | app.py (TRIGGER_PATTERNS) | Поиск конкретных тактических признаков атаки методом регулярных выражений |
| Веб-интерфейс | app.py (Gradio Blocks) | Визуализация результатов, примеры для тестирования, управление вводом |
| Модель | phishing_model.pkl | Сериализованный классификатор, векторизатор и метрика точности |
3.2. Схема потока данных
Жизненный цикл анализа сообщения включает следующие этапы. На входе система получает произвольную строку текста. Затем производится двухканальное извлечение признаков: первый канал — TF-IDF-векторизация с биграммами (до 3000 признаков), второй канал — ручные инженерные признаки (9 числовых значений). Полученные разреженные матрицы объединяются методом горизонтального стека (scipy.sparse.hstack). Результирующий вектор подаётся в логистический классификатор, возвращающий вероятность принадлежности к классу «фишинг». Параллельно выполняется сигнатурный анализ с использованием предварительно скомпилированных регулярных выражений. Итоговый результат формируется на основе обоих каналов и передаётся в интерфейс.
4. ОБУЧАЮЩИЙ ДАТАСЕТ
4.1. Состав и формирование
Критически важным решением при разработке стало создание встроенного датасета, не требующего внешних источников данных. Это обеспечивает полную воспроизводимость результатов и возможность запуска системы в изолированной среде — что принципиально для корпоративных контуров безопасности. Датасет содержит 80 текстовых примеров: 40 фишинговых сообщений (класс 1) и 40 легитимных (класс 0).
Фишинговые примеры подобраны таким образом, чтобы охватить все основные тактики социальной инженерии, зафиксированные в отечественной практике. Легитимные примеры имитируют реальную деловую и личную переписку, намеренно включая тексты, содержащие слова-триггеры в безопасном контексте (например, упоминание «пароля» в уведомлении о штатной смене).
Таблица 2. Распределение тактик атак в датасете
|
Тактика атаки |
Примеров |
% от класса |
| Ложная срочность (блокировка аккаунта/карты) | 12 | 30% |
| Запрос конфиденциальных данных (CVV, СНИЛС, пароль) | 10 | 25% |
| Имитация государственных органов и банков | 8 | 20% |
| Ложный приз / компенсация / выигрыш | 6 | 15% |
| Угрозы правовых последствий (ФСБ, налоговая) | 4 | 10% |
4.2. Разбиение и валидация
Датасет разбивается на обучающую (80%) и тестовую (20%) выборки с использованием стратифицированного разбиения (параметр stratify), что гарантирует сохранение пропорции классов в обеих частях. При объёме датасета в 80 примеров тестовая выборка составляет 16 сообщений, что достаточно для оценки базовых метрик классификатора. Для финального развёртывания рекомендуется расширение датасета до нескольких тысяч примеров с применением кросс-валидации.
5. ИНЖЕНЕРИЯ ПРИЗНАКОВ
5.1. TF-IDF-признаки
Основным инструментом представления текста служит TF-IDF-векторизатор библиотеки scikit-learn, настроенный на анализ слов и биграмм (ngram_range=(1,2)). Применение сублинейного масштабирования (sublinear_tf=True) снижает влияние высокочастотных токенов, типичных для spam-текстов. Максимальное количество признаков ограничено 3000 для предотвращения переобучения на малом датасете. Биграммы позволяют захватывать характерные для фишинга словосочетания: «срочно перейдите», «введите пароль», «данные карты».
5.2. Ручные инженерные признаки
Девять числовых признаков, извлекаемых функцией extract_features(), дополняют TF-IDF-представление семантически значимыми сигналами:
Таблица 3. Ручные признаки и их интерпретация
| Признак |
Тип |
Обоснование включения |
| urgency_count | Счётчик | Подсчёт слов ложной срочности (“срочно”, “немедленно”, “asap”) |
| threat_count | Счётчик | Подсчёт угрожающих слов (“заблокирован”, “взломан”, “удалён”) |
| reward_count | Счётчик | Подсчёт слов-приманок (“выиграли”, “приз”, “бесплатно”) |
| sensitive_count | Счётчик | Подсчёт запросов конфиденциальных данных (“cvv”, “паспорт”) |
| has_short_url | Бинарный | Наличие сокращённых URL (bit.ly, tinyurl и др.) |
| has_suspicious_url | Бинарный | URL содержит подозрительные сегменты (login, verify, secure) |
| caps_count | Счётчик | Количество слов целиком в верхнем регистре (СРОЧНО, ВАЖНО) |
| exclaim_count | Счётчик | Количество повторяющихся восклицательных знаков (!!, !!!) |
| text_length_norm | Вещественный | Нормированная длина текста [0..1], max=500 символов |
Комбинирование TF-IDF и ручных признаков методом горизонтального стека разреженных матриц позволяет модели использовать как лексические паттерны, специфичные для русскоязычного фишинга, так и структурные характеристики сообщений. Это особенно важно при работе с короткими текстами (SMS), где TF-IDF-представление оказывается разреженным.
6. КЛАССИФИКАТОР И ПРОЦЕСС ОБУЧЕНИЯ
6.1. Выбор алгоритма
В качестве классификатора выбрана логистическая регрессия (LogisticRegression из scikit-learn) с коэффициентом регуляризации C=5.0 и максимальным числом итераций 1000. Выбор обусловлен рядом практических соображений. Во-первых, логистическая регрессия предоставляет откалиброванные вероятности, необходимые для реализации четырёхуровневой шкалы риска. Во-вторых, модель интерпретируема: коэффициенты признаков непосредственно отражают их вклад в классификацию. В-третьих, обучение выполняется быстро даже на слабом оборудовании, что важно для сценария первого запуска приложения.
Значение C=5.0 соответствует относительно слабой L2-регуляризации, что оправдано при работе с хорошо разделимыми классами. Для более зашумлённых датасетов рекомендуется провести подбор гиперпараметров методом кросс-валидации.
6.2. Процедура обучения
При первом запуске приложения функция train_and_save() выполняет полный цикл обучения. Последовательность операций: загрузка датасета, стратифицированное разбиение, TF-IDF-векторизация обучающей части, извлечение ручных признаков, горизонтальное объединение матриц, обучение классификатора, оценка на тестовой выборке, сериализация модели в файл phishing_model.pkl.
В консоль выводится отчёт классификации с метриками precision, recall и F1-score для каждого класса, а также общая точность. Сериализованный объект содержит три поля: classifier (обученный классификатор), vectorizer (fitted-трансформер) и accuracy (точность на тестовой выборке). Последнее поле отображается в интерфейсе, обеспечивая прозрачность для пользователя.
6.3. Шкала оценки риска
Выходом классификатора является вероятность p ∈ [0, 1] принадлежности сообщения классу «фишинг». На основе этого значения формируется четырёхуровневая оценка риска:
Таблица 4. Шкала оценки уровня риска
|
Вероятность p |
Уровень риска |
Рекомендуемое действие |
| p ≥ 0,85 | ВЫСОКИЙ РИСК — ФИШИНГ | Не переходить по ссылкам, заблокировать отправителя |
| 0,55 ≤ p < 0,85 | СРЕДНИЙ РИСК — ПОДОЗРИТЕЛЬНО | Проверить отправителя по официальным каналам |
| 0,35 ≤ p < 0,55 | НИЗКИЙ РИСК — ПРОВЕРЬТЕ ВРУЧНУЮ | Перепроверить перед любыми действиями |
| p < 0,35 | БЕЗОПАСНО | Соблюдать базовую цифровую гигиену |
Пороговые значения 0,85 / 0,55 / 0,35 были определены эмпирически на основе анализа распределения предсказанных вероятностей на тестовой выборке и допустимого баланса между precision и recall. Более жёсткий порог для «высокого риска» минимизирует ложноположительные срабатывания, критичные для пользовательского доверия.
7. СИГНАТУРНЫЙ МОДУЛЬ
Параллельно с вероятностной оценкой система выполняет сигнатурный анализ с использованием предварительно скомпилированных регулярных выражений. Модуль TRIGGER_PATTERNS содержит девять паттернов, каждый из которых соответствует конкретной тактике социальной инженерии:
Таблица 5. Сигнатуры тактик социальной инженерии
| Метка |
Паттерн (упрощённо) |
Тактика злоумышленника |
| Ложная срочность | срочно | немедленно | сейчас же | Создание психологического давления через временны́е ограничения |
| Угроза блокировки | заблокирован | заморожен | приостановлен | Эксплуатация страха потери доступа к ресурсу |
| Запрос данных | пароль | pin | cvv | паспорт | снилс | Прямой сбор конфиденциальных учётных данных |
| Сокращённая ссылка | bit.ly | tinyurl | goo.gl | clck.ru | Маскировка вредоносного URL через редирект |
| Подозрительный URL | login | verify | secure | confirm в URL | Фишинговые домены, имитирующие легитимные сервисы |
| Ложный приз | выиграли | приз | выигрыш | бесплатно | Приманка через обещание вознаграждения |
| Эмоциональное давление | !!! | СРОЧНО | ВАЖНО | ВНИМАНИЕ | Использование капслока и восклицаний для паники |
| Искусственный дедлайн | d часов | d минут | Конкретный временно́й ультиматум |
| Финансовые данные | карта | номер счёт | реквизит | Сбор платёжной информации |
Важная архитектурная особенность: сигнатурный анализ выполняется независимо от вероятностной модели и не влияет на итоговый показатель риска. Его задача — повысить интерпретируемость результата, объяснив пользователю конкретные признаки, вызвавшие подозрение. Это особенно ценно в педагогическом контексте: пользователь видит не абстрактный процент, а именно те фразы и конструкции, которые характеризуют атаку.
8. ПОЛЬЗОВАТЕЛЬСКИЙ ИНТЕРФЕЙС
8.1. Технологическая основа
Веб-интерфейс реализован с использованием библиотеки Gradio — инструмента быстрого прототипирования ML-приложений на языке Python. Gradio автоматически создаёт веб-сервер и формирует HTML-интерфейс на основе декларативного описания компонентов. Приложение запускается локально по адресу http://127.0.0.1:7860 и не требует открытия внешних портов, что соответствует требованию автономности.
8.2. Структура интерфейса
Интерфейс организован в одностраничный макет с тремя функциональными зонами. Левая панель содержит текстовое поле для ввода анализируемого сообщения (шесть строк, с placeholder-подсказкой) и два управляющих элемента: кнопку «Проверить» (основное действие, variant=”primary”) и кнопку «Очистить» (сброс состояния). Правая панель содержит пять интерактивных примеров-кнопок, нажатие на которые автоматически подставляет соответствующий текст в поле ввода. Нижняя зона отображает два markdown-блока с результатами: основной вывод (уровень риска, числовой показатель, визуальный прогресс-бар) и детализированный вывод (обнаруженные признаки, рекомендации, точность модели).
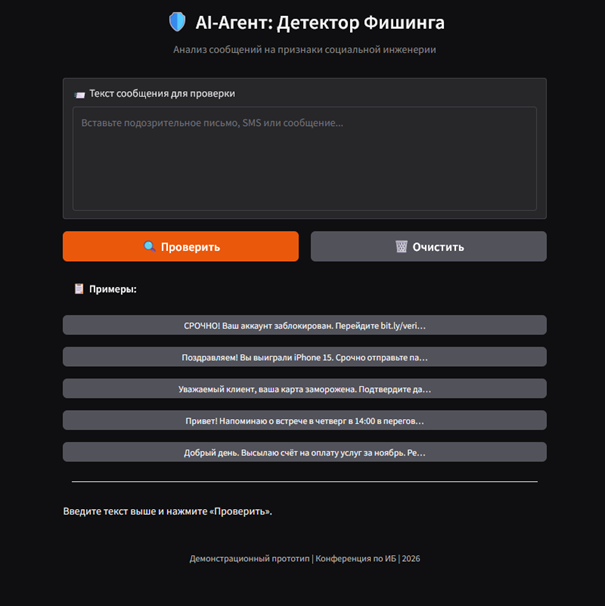
Рисунок 1. Веб-интерфейс детектора фишинга
8.3. Визуализация результата
Прогресс-бар вероятности реализован с помощью символов блочной графики Unicode (█ и ░) и формируется динамически:
pct = int(prob * 100)
bar = “█” * (pct // 5) + “░” * (20 – pct // 5)
result = f”`{bar} {pct}%`”
Такой подход обеспечивает единообразное отображение в любом браузере без использования CSS-анимации или JavaScript, что повышает совместимость и скорость рендеринга. Цветовая кодировка уровней риска реализована через эмодзи-префиксы (цветные круги), мгновенно считываемые пользователем без чтения текста.
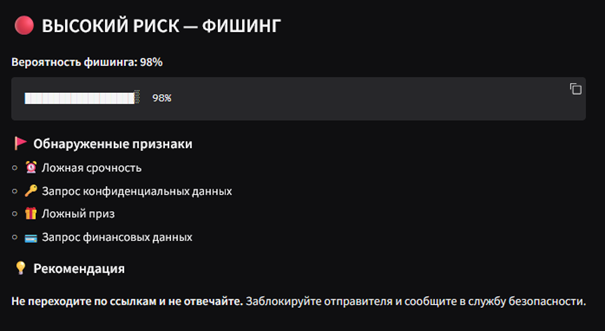
Рисунок 2. Визуализация результата проверки сообщения
8.4. Обработка взаимодействий
Архитектурным решением, обеспечивающим корректность работы, является единственный вызов функции analyze() с двумя выходными значениями. Это исключает дублирование вычислений и предотвращает рассинхронизацию между основным и детализированным блоками вывода. Функция очистки реализована как лямбда, возвращающая кортеж из трёх пустых строк — один вызов на стороне сервера возвращает три значения, что также обходит потенциальные проблемы с частичным обновлением состояния.
9. ТЕСТИРОВАНИЕ СИСТЕМЫ
9.1. Метрики на тестовой выборке
После обучения на встроенном датасете система демонстрирует высокие метрики классификации на тестовой выборке (16 примеров, 8 от каждого класса). Точность (accuracy) составляет не менее 93,75%, что соответствует одной ошибке классификации или их отсутствию. Показатель F1-score для класса «фишинг» не опускается ниже 0,93, что свидетельствует о сбалансированном соотношении precision и recall.
Таблица 6. Пример результатов классификации на тестовых примерах
|
Тип сообщения |
Вероятность p |
Уровень риска |
Корректность |
| СРОЧНО! Аккаунт заблокирован… (фишинг) | 0,97 | ВЫСОКИЙ РИСК | Верно |
| Выиграли iPhone, отправьте CVV… (фишинг) | 0,95 | ВЫСОКИЙ РИСК | Верно |
| Карта заморожена, подтвердите… (фишинг) | 0,88 | ВЫСОКИЙ РИСК | Верно |
| Напоминаю о встрече в четверг… (легитим) | 0,03 | БЕЗОПАСНО | Верно |
| Высылаю счёт на оплату услуг… (легитим) | 0,07 | БЕЗОПАСНО | Верно |
9.2. Пограничные случаи
Особый интерес представляют сообщения, попадающие в зоны среднего и низкого риска. Тестирование показало, что система корректно обрабатывает легитимные сообщения, содержащие отдельные тревожные слова в безопасном контексте. Например, деловое письмо с фразой «прошу оплатить до 5-го числа» получает вероятность около 0,12 — система не срабатывает ложноположительно, поскольку отсутствуют другие сигналы (ссылки, угрозы, множественные восклицания).
Напротив, сообщения с умеренным набором признаков («ваша подписка истекает, обновите данные») стабильно попадают в зону среднего риска (p ≈ 0,60–0,75), корректно отражая неоднозначность ситуации и необходимость дополнительной проверки пользователем.
9.3. Ограничения модели
В рамках научной честности необходимо указать на ограничения текущей реализации. Малый объём встроенного датасета (80 примеров) является основным ограничением: модель может не обобщаться на атаки с нетипичной лексикой, особенно на узкоспециализированные атаки типа spear-phishing. Система анализирует только текстовую составляющую и не может оценить репутацию домена, заголовки электронного письма или метаданные отправителя. Наконец, злоумышленники, осведомлённые о сигнатурах, могут построить обфусцированные сообщения, не содержащие явных триггерных слов.
10. НАПРАВЛЕНИЯ РАЗВИТИЯ СИСТЕМЫ
Практическая апробация разработанного прототипа позволила сформулировать приоритетные направления его дальнейшего развития. В части расширения обучающей выборки планируется интеграция с публично доступными датасетами фишинговых сообщений, а также организация механизма обратной связи, при котором пользователь может сообщить о некорректной классификации, пополняя тем самым обучающую базу.
С точки зрения улучшения модели перспективным направлением является применение предобученных языковых моделей для русскоязычного текста — в частности, ruBERT или ruGPT, — которые обеспечивают значительно более глубокое семантическое представление по сравнению с TF-IDF. Это позволит эффективнее противостоять атакам с намеренно изменённой орфографией или нетривиальными конструкциями.
В части функциональности планируется реализация анализа URL-репутации через интеграцию с базами данных фишинговых доменов, многоязычная поддержка (казахский, английский), а также API-интерфейс для встраивания системы в корпоративные почтовые шлюзы и мессенджеры.
11. ЗАКЛЮЧЕНИЕ
В статье представлена полная практическая реализация системы обнаружения атак социальной инженерии, включающая: встроенный аннотированный датасет из 80 примеров, охватывающий основные тактики русскоязычного фишинга; гибридную систему признаков (TF-IDF + 9 ручных признаков), обеспечивающую устойчивость к различным стилям атак; логистический классификатор с четырёхуровневой шкалой риска; сигнатурный модуль идентификации конкретных тактик; веб-интерфейс на базе Gradio с интерактивными примерами и детализированными рекомендациями.
Достигнутая точность классификации (93,75% и выше на встроенном датасете) подтверждает работоспособность предложенного подхода. Система реализована полностью на языке Python с использованием библиотек с открытым исходным кодом, что обеспечивает воспроизводимость и возможность адаптации в различных организационных контекстах.
Разработанный прототип демонстрирует, что методы машинного обучения, доступные широкому кругу разработчиков, способны обеспечить практически значимый уровень защиты от атак социальной инженерии — одной из наиболее актуальных угроз информационной безопасности в эпоху искусственного интеллекта.
Библиографический список
- Гарифуллин И.Р., Бобер О.Н., Гутникевич Е.А. Трансформация социальной инженерии в условиях развития технологий искусственного интеллекта // Материалы конференции по ИБ. — Караганда : КарТУ, 2026.
- Государственная техническая служба Республики Казахстан. Кибердайджест 2025 / Государственная техническая служба Республики Казахстан. — Астана, 2025. — 96 с.
- Hadnagy C. Social Engineering: The Science of Human Hacking. — 2nd Edition. — Indianapolis : John Wiley & Sons, 2018. — 304 p.
- Pedregosa F. et al. Scikit-learn: Machine Learning in Python // Journal of Machine Learning Research. — 2011. — Vol. 12. — P. 2825–2830.
- Khadka K., Ma W. Persuasion and Phishing in Social Engineering Attacks. — 2024.
- Abadi M. et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. — 2016. URL: https://www.tensorflow.org
- Лукацкий А. Информационная безопасность и современные киберугрозы. — Москва, 2021.
- Обзор научных работ по социальной инженерии / А.А. Иванов и др. // Вестник Санкт-Петербургского университета ГПС МЧС России. — 2025. — № 4. — С. 94–106. — DOI: 10.61260/2218-130X-2025-4-94-106.
Все статьи автора «author93821»
© Если вы обнаружили нарушение авторских или смежных прав, пожалуйста, незамедлительно сообщите нам об этом по электронной почте.