ПРИМЕНЕНИЕ ВЕЙВЛЕТ-ПРЕОБРАЗОВАНИЯ В ЗАДАЧАХ ИДЕНТИФИКАЦИИ ПО ГОЛОСУ
Волгоградский государственный технический университет
Аннотация
Данная статья посвящена сравнительному анализу эффективности применения вейвлет-преобразований с различными базисами для параметризации голосовых образцов в задаче текстонезависимой идентификации. Проведенное исследование позволяет утверждать, что системы идентификации по голосу, использующие вейвлет-анализ не уступают по эффективности системам, в которых применяется фурье-анализ. В процессе проведения исследования создан прототип автоматизированной системы для текстонезависимой идентификации пользователей.
Ключевые слова: вейвлет, вейвлет-анализ, идентификация по голосу, пакетное вейвлет преобразование, текстонезависимая идентификация., фурье-анализ, цифровая обработка сигналов
SPEAKER RECOGNITION METHOD USING WAVELET TRANSFORMATION
Volgograd state technical university
Abstract
This paper contemplates comparative analysis of the effectiveness of wavelet transforms with different wavelet-families for voice samples parameterization. Basing upon the undertaken study the author deduces that speaker identification systems using wavelet analysis effective as systems that use Fourier analysis. In the course of the study, a prototype of automatic speaker identification system have been created.
Рубрика: 01.00.00 ФИЗИКО-МАТЕМАТИЧЕСКИЕ НАУКИ
Библиографическая ссылка на статью:
Фролов Г.О. Применение вейвлет-преобразования в задачах идентификации по голосу // Современные научные исследования и инновации. 2013. № 5 [Электронный ресурс]. URL: https://web.snauka.ru/issues/2013/05/24295 (дата обращения: 03.08.2026).
Введение
Вейвлет-преобразование – современное обобщение спектрального анализа, которое, в отличие от традиционно применяемого для анализа сигналов Фурье-преобразования, обеспечивает двумерную развертку исследуемого одномерного сигнала. При этом частота и координата рассматриваются как независимые переменные.
Основная проблема в задаче идентификации по голосу заключается в поиске такого метода параметризации исходных образцов голоса, который позволил бы выделить из исходного сигнала индивидуальные особенности говорящего. При этом обладающий не слишком высокой вычислительной сложностью и формирующий максимально компактные характеристические векторы образцов голоса.
Большая часть подобных методов (MFCC, LPCC) основана на преобразовании Фурье и предположении о квазистационарности речевого сигнала на коротких промежутках времени (10-30 мс), что является всего лишь допущением.
Эта статья посвящена анализу применимости в задачах текстонезависмой идентификации ряда методов параметризации основанных на вейвлет-преобразованиях с различными базисами и более популярных методов, использующих для параметризации мэл-частотные кепстральные коэффициенты и кепстральные коэффициенты на основе линейного предсказания.
Описание конкурирующих методик
Задача параметризации речевого сигнала стоит наиболее остро и до сих пор не решена в полной мере. К наиболее популярным методам параметризации можно отнести кепстральный анализ и анализ спектра модуляции.
Большинство современных алгоритмов параметризации сосредотачивают усилия на извлечении частотной характеристики речевого тракта человека, отбрасывая при этом характеристики сигнала возбуждения.
Для отделения сигнала возбуждения от сигнала речевого тракта прибегают к кепстральному анализу. Схематически этот метод представлен на рисунке 1.

Рисунок 1 – Схема вычисления кепста
где FFT – блок быстрого преобразования Фурье сигнала (БПФ), LOG – блок логарифмирования спектра, IFFT – блок обратного быстрого преобразования Фурье (ОБПФ).
После параметризации сигнала такими алгоритмами формируется K n-мерных характеристических векторов, где K равно числу фреймов, а n – числу используемых кепстральных коэффициентов (обычно от 10 до 40), которые передаются используемому в системе классификатору.
Методика параметризации образцов
В задаче текстонезависимой идентификации по голосу характер и длительность высказывания, по которому требуется идентифицировать диктора, априори неизвестны. Поэтому при параметризации на первый план выходит выделение артикуляционных особенностей говорящего в моменты межфонемных переходов в его речи. Преобразование Фурье плохо подходит для параметризации нестационарных сигналов подобного рода, поэтому нами было принято решение проанализировать перспективы применения дискретного вейвлет-преобразования для этой задачи.
В исследовательских целях нами был разработан метод, основанный на пакетном вейлвет-преобразовании, схема которого представлена на рисунке 2.
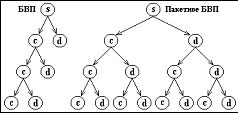
Рисунок 2 – Схема пакетного вейвлет-преобразования
Схематически реализованный метод представлен ниже:
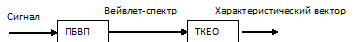
Рисунок 3 – Схема метода
Где ПБВП – пакетное вейвлет-преобразование (в исследовании использовались вейвлет-базисы Добеши, Simlet и Coiflet различных порядков) с числом уровней декомпозиции от 2 до 8.
ТKЕО (Teager Kaiser Energy Operator ) – 
где: N = Len/2^n
где: Len – длина кадра в отсчетах сигнала, а n – число уровней декомпозиции
применяемый для каждого из 2^n полученных поддиапазонов, чтобы сформировать характеристический вектор размерностью 2^n, где n – число уровней декомпозиции сигнала.
Перед обработкой сигнала проводилось предусиление (pre-emphasis), нормализация
Где: µ – среднее арифметическое
ơ – среднеквадратичное отклонение
и разбиение на непересекающиеся кадры длиной от 256 до 4096 отсчетов сигнала.
Сформированные векторы признаков передавались классификатору, работающему по алгоритму «K ближайших соседей»[4], где K выбрано равным 36, в качестве меры расстояния используется Евклидова метрика.
Для проведения исследования использовались образцы голосов из бесплатного корпуса Chains (CHAracterizing Individual Speakers)[], содержащего образцы голосов 36 дикторов записанных в два этапа с разницей в два месяца в различном окружении. Формат: mono, 16000Гц, 16 бит PCM Всего 1332 образца общей длительностью около 360 минут.
Результаты исследования
Первый этап исследования заключался в определении оптимального вейлвет-базиса для разложения сигнала. При этом использовались кадры длиной 512 отсчетов и 5 уровней разложения. В качестве классификатора использовался алгоритм ближайшего соседа. Для обучения системы были использованы фрагменты длиной ~2,5 минуты для каждого диктора. В качестве тестовых образцов использовались все остальные доступные в корпусе Chains фрагменты. Всего в количестве 1296 образцов голоса для 36 дикторов. Для сравнения приводятся результаты алгоритмов параметризации LPCC и MFCC, полученные на том же наборе данных.
По результатам этого этапа в качестве вейвлет-базиса был выбран базис Добеши-20.
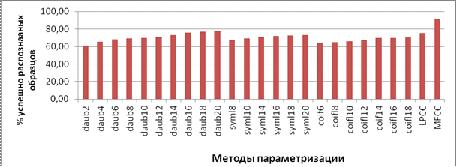
Рисунок 4 – Сравнительная эффективность методов параметеризации
Второй этап заключался в определение оптимальной длины анализируемого кадра для метода.
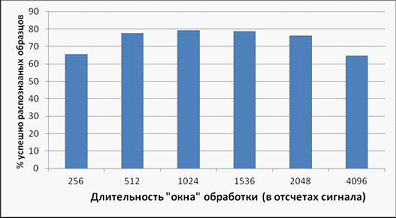
Рисунок 5 – Зависимость точности идентификации от длины кадра
Наибольший процент распознавания удалось получить с использованием окна в 1024 отсчета сигнала.
На третьем этапе устанавливалась зависимость качества идентификации от количества уровней вейвлет-разложения сигнала.
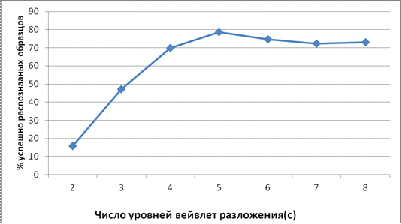
Рисунок 6 – Зависимость точности идентификации от числа уровней разложения
При малом количестве уровней разложения размерность характеристического вектора невелика и идентификация проходит быстрее, но точность распознавания падает. С увеличением количества уровней разложения растет только вычислительная сложность параметризации и сравнения образцов – точность идентификации же не только не растет, но даже несколько снижается.
Последний этап заключался в определении минимально необходимой длительности тренировочных и тестовых образцов для идентификации диктора.
Сначала при фиксированном наборе из 1296 образцов голосов 36 дикторов длина тренировочных образцов голоса для каждого диктора изменялась от 2 до 18 с :
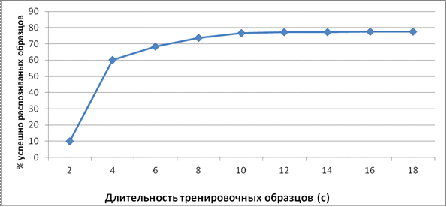
Рисунок 7 – Зависимость точности идентификации от длительности обучающих материалов
Длительность обучающих образцов перестает оказывать заметное влияние на процент успешной идентификации при достижении значения ~16 c
Также было исследовано влияние длительности тестового образца на точность идентификации. Для этого при фиксированной длительности обучающих образцов (порядка 1 минуты), изменялась длительность образцов голоса 36 дикторов, используемых для эксперимента.
Точность идентификации практически перестает возрастать при увеличении длительности тестовых образцов более 5 с
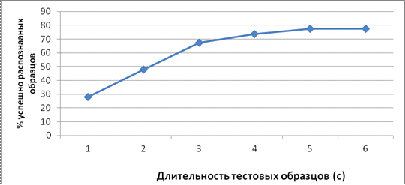
Рисунок 8 – Зависимость точности идентификации от длительности тестовых образцов
Заключение
Проведенное исследование позволяет утверждать, что использование вейвлет-преобразования для параметризации голосовых образцов позволяет добиться сопоставимой с популярными методами на основе кепстрального анализа точности текстонезависимой идентификации по голосу. Из рассмотренных базисов наилучшие результаты обеспечивает базис добеши 20 порядка с длиной кадра 1536 отсчетов сигнала и 5-ю уровнями разложения.
Библиографический список
-
X.Huang, A.Acero, H.Hon. Spoken Language Processing: A guide to theory, algorithm, and system development. Prentice Hall, 2001.
-
H.Hermansky. Perceptual Linear Predictive (PLP) Analysis of Speech. The Journal of the Acoustical Society of America, 87(4): 1738-1752, 1990.
-
F.Zheng, G.Zhang, Z.Song. Comparison Of Different Implementations Of MFCC. J. Computer Science & Technology, 16(6): 582-589, 2001.
-
Paredes R., Vidal E., Casacuberta F. Local features for speaker recognition // SPR 2004. International Workshop on Statistical Pattern Recognition. LNCS 3138 of Lecture Notes in Computer Science. 2004. P. 1087-1095.
-
Шарий Т.В. О проблеме параметризации речевого сигнала в современных системах распознавания речи. Вестник Донецкого национального университета №2 – 2008
© Если вы обнаружили нарушение авторских или смежных прав, пожалуйста, незамедлительно сообщите нам об этом по электронной почте.