Введение
Высоконагруженный API – средство интеграции, которое стало самостоятельным слоем бизнес-критичной инфраструктуры. Через него проходят платежные операции, пользовательские события, запросы мобильных приложений, потоковые обновления и межсервисные вызовы. В условиях, когда JavaScript остается одной из наиболее массовых технологий разработки, а в опросе Stack Overflow 2025 его использовали 66% всех респондентов и 68,8% профессиональных разработчиков, архитектура Node.js-сервисов сохраняет практическую значимость для серверных платформ [1].
Актуальность данной темы определяется тем, что рост нагрузки редко ограничивается увеличением числа запросов. На поведение API влияют распределенность данных, вложенность клиентских запросов, стоимость сериализации, сетевые очереди, задержки в Linux-стеке, ограничения памяти, политика контейнерного масштабирования и качество наблюдаемости. В исследованиях по защищенным API на Node.js подчеркивается роль API Gateway, Backend for Frontend, CQRS и Strangler Fig как моделей, связывающих масштабируемость, модульность и контроль доступа [2]. Проблема исследования заключается в разрыве между выбором популярной технологии и реальной производительностью сервисного контура. Цель статьи состоит в анализе архитектурных моделей построения высоконагруженных API и систематизации методов повышения производительности серверных сервисов. Для достижения цели рассматриваются уровни интерфейсного проектирования, протокольного взаимодействия, исполнения в Node.js, оптимизации Linux и эксплуатации контейнерной инфраструктуры.
Архитектурный контур высоконагруженного API
Архитектура высоконагруженного API начинается с разграничения внешнего и внутреннего контуров взаимодействия. Внешний контур должен обеспечивать стабильный контракт, управление версиями, аутентификацию, ограничение частоты запросов и защиту от аномальной активности. Внутренний контур ориентирован на независимое масштабирование сервисов, снижение связности и управляемое распространение отказов. Для финтех-приложений, где API связан с платежными сценариями и требованиями к высокой доступности, особенно важны избыточность, идемпотентность операций, изоляция критических сервисов и предсказуемые деградационные режимы [3]. В банковских middleware-проектах переход от монолитной логики к микросервисной модели оценивается через CPU, RAM, задержку, пропускную способность, частоту ошибок, долю успешных операций и время восстановления [4].
Сравнение базовых моделей приведено в Таблице 1.
Таблица 1. Архитектурные модели высоконагруженного API
|
Модель |
Назначение |
Сильная сторона |
Ограничение |
Уместный контекст |
|
API Gateway |
Единая точка входа, маршрутизация, лимиты, авторизация |
Централизация политики безопасности и контроля трафика |
Риск перегрузки шлюза при слабом горизонтальном масштабировании |
Публичные API, партнерские интеграции, мобильные приложения |
|
Backend for Frontend |
Адаптация API под тип клиента |
Снижение избыточной передачи данных и упрощение клиентской логики |
Увеличение числа сервисных фасадов |
Разные web, mobile и partner-клиенты |
|
CQRS и асинхронная шина |
Разделение команд, чтения и событий |
Сглаживание пиков и независимое масштабирование потоков |
Сложность согласованности данных |
Заказы, платежные события, уведомления, аналитика |
|
Strangler Fig |
Постепенная замена монолита сервисами |
Снижение миграционного риска |
Длительный период гибридной эксплуатации |
Модернизация унаследованных платформ |
|
Сервис-сервис gRPC |
Быстрые внутренние вызовы по строгому контракту |
Компактная сериализация и поддержка streaming |
Более высокая стоимость отладки и шлюзования |
Внутренние микросервисы с интенсивным обменом |
Данные модели не являются взаимозаменяемыми шаблонами. Они образуют архитектурный набор, в котором API Gateway отвечает за внешний контроль, BFF снижает сложность потребления, CQRS отделяет пользовательские команды от чтения, а Strangler Fig позволяет переносить нагрузку с унаследованных узлов без одномоментной перестройки всей платформы. Выбор модели должен начинаться с профиля нагрузки: доли чтения и записи, допустимой задержки, частоты изменений контрактов, распределения клиентов и требований к отказоустойчивости. Если доминирует чтение, наибольший эффект дают кэширование и специализированные read-модели. Если преобладают короткие внутренние вызовы, больший вклад может дать gRPC вместе со строгими схемами данных.
Протоколы взаимодействия и прикладная производительность
На протокольном уровне REST, GraphQL и gRPC решают разные задачи. REST остается простым и прозрачным вариантом для стабильных ресурсных интерфейсов. GraphQL удобен при сложных клиентских представлениях и переменной вложенности данных. gRPC рационален для сервис-сервис обмена, где важны бинарная сериализация, HTTP/2, streaming и контрактность через Protocol Buffers. Экспериментальное сравнение REST, GraphQL и gRPC в микросервисной среде с Redis и MySQL показало, что gRPC демонстрировал меньшую задержку ответа при запросах от 100 до 500, REST отличался более низкой загрузкой CPU, а GraphQL давал большую нагрузку на процессор в сценариях с вложенными данными [5]. На практике это означает, что выбор протокола должен опираться не на общий рейтинг технологий, а на структуру данных, тип клиента и допустимую цену вычислений.
На Рисунке 1 представлена типовая схема прохождения запроса через высоконагруженный API-контур.
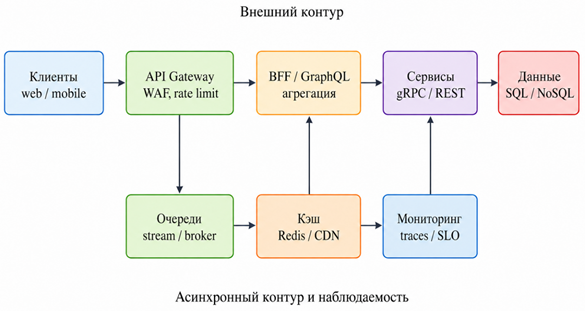
Рисунок 1. Контур обработки запроса в высоконагруженной API-платформе
Схема показывает, что производительность формируется на нескольких связанных участках. Даже быстрый рантайм не компенсирует неоптимальный запрос к базе данных, отсутствие кэша, избыточную агрегацию или слабое лимитирование входящего трафика. По этой причине проектирование API должно включать не только выбор фреймворка, но и описание очередей, кэша, схемы трассировки и правил деградации. В Node.js-сервисах особое значение имеют неблокирующий ввод-вывод, состояние event loop, пул соединений, backpressure, профилирование долгих callbacks и аккуратная работа с CPU-интенсивными задачами. В исследованиях по производительности Node.js под высокой сетевой нагрузкой выделяются кластеризация процессов, кэширование, настройка таймаутов, оптимизация сериализации и контроль блокирующих операций [6].
Практические направления оптимизации сведены в Таблице 2.
Таблица 2. Уровни оптимизации серверных сервисов и метрики контроля
|
Уровень |
Метод |
Метрика контроля |
Риск неправильного применения |
|
API-контракт |
Версионирование, схемы, идемпотентность |
Ошибки 4xx/5xx, частота несовместимых изменений |
Разрастание версий и поддержка устаревших клиентов |
|
Node.js runtime |
Кластеризация, worker threads, контроль event loop lag |
p95/p99 latency, event loop delay, CPU |
Маскировка CPU-bound логики без изменения алгоритма |
|
Кэш и данные |
Redis, CDN, read-модели, пул соединений |
Cache hit ratio, время запроса к БД |
Устаревшие данные и лавина промахов кэша |
|
Протокол |
REST, GraphQL, gRPC по профилю нагрузки |
Размер ответа, CPU, время сериализации |
Избыточное усложнение интерфейса |
|
Операционная система |
Настройка памяти, сетевых очередей, eBPF/XDP |
RSS, page faults, softirq, packet drops |
Сложность диагностики и зависимость от ядра |
|
Инфраструктура |
Контейнеры, оркестрация, autoscaling, GitOps |
Время восстановления, saturation, SLO |
Неучтенные лимиты CPU/RAM и сетевые оверхеды |
Таблица фиксирует прикладной вывод: оптимизация не должна сводиться к локальной правке кода. Устойчивый эффект достигается при связке контрактного проектирования, профилирования рантайма, контроля базы данных и сетевого слоя. Для CPU-интенсивных участков допустимо выносить вычисления в worker threads или нативные модули, а для I/O-интенсивных сервисов важнее ограничивать очереди и управлять временем ожидания. Дополнительный резерв создают низкоуровневые расширения. Исследования по связке Node.js с Rust и WebAssembly показывают, что нативные компоненты могут значительно ускорять вычислительные участки, хотя такая интеграция повышает требования к сборке, тестированию и контролю безопасности [7].
Системная оптимизация серверного исполнения
Серверная производительность API зависит от операционной системы не меньше, чем от прикладного фреймворка. В Linux критичны управление физической и виртуальной памятью, поведение сборщика мусора в Node.js, работа page cache, сетевые очереди, прерывания, переключения контекста и копирование данных между пространством ядра и пользовательским пространством. Исследования по управлению памятью в Linux-средах высоконагруженных сервисов связывают стабильность приложения с контролем фрагментации, swap, page faults и режимов выделения памяти [8]. Сетевой путь пакета также требует отдельного анализа. Для уменьшения задержек применяются extended Berkeley Packet Filter (eBPF), eXpress Data Path (XDP), Data Plane Development Kit (DPDK), настройка interrupt coalescing, receive-side scaling и очередей сетевых интерфейсов. В работе по уменьшению сетевых задержек в Linux-системах отдельно выделены источники издержек при переходе между ядром и пользовательским пространством, а также роль eBPF/XDP и DPDK в сокращении пути обработки пакета [9].
На Рисунке 2 показана разница во времени достижения разных точек обработки пакета по данным экспериментального исследования eBPF-сетевых приложений [10].

Рисунок 2. Время достижения точек обработки пакета в сетевом стеке Linux
График показывает, что XDP располагается ближе к сетевому драйверу, а пользовательский socket-путь связан с более длинной цепочкой обработки. Это объясняет интерес к eBPF/XDP для балансировщиков, фильтров, телеметрии и других задач, где логика может быть безопасно перенесена в ранний участок сетевого пути. При этом перенос логики в ядро не гарантирует ускорения для любого API. В тех же экспериментах зафиксировано, что выгода зависит от доли запросов, проходящих по fast path, а часть сценариев может получить рост задержки slow path. Исследования AF_XDP также показывают, что достижение микросекундных задержек возможно только при внимательной настройке параметров сокетов, очередей и прикладного цикла обработки [11].
Контейнерная инфраструктура добавляет собственный слой решений. Контейнеризация и оркестрация повышают адаптивность, упрощают развертывание и позволяют применять многоуровневые политики безопасности, но требуют строгого контроля лимитов ресурсов, сетевых плагинов, секретов и образов [12]. В ежегодном исследовании CNCF за 2025 год указано, что 82% пользователей контейнеров запускали Kubernetes в production-средах, а 98% опрошенных организаций применяли cloud native-подходы [13]. Для высоконагруженного API это означает необходимость сочетать горизонтальное масштабирование с ограничением входящего трафика, circuit breaker, автоматическим откатом, изоляцией критичных сервисов и сквозной трассировкой. Без этих механизмов autoscaling может лишь перенести перегрузку с приложения на базу данных, очередь или сетевой плагин.
Заключение
Архитектура высоконагруженного API должна рассматриваться как многоуровневый контур, где интерфейсный контракт, протокол обмена, логика сервиса, память, сеть и контейнерная платформа влияют на общий результат. Универсальная модель отсутствует: API Gateway, BFF, CQRS, Strangler Fig, REST, GraphQL и gRPC эффективны только при соответствии профилю нагрузки и эксплуатационным ограничениям. Для прикладных сервисов ключевыми остаются профилирование event loop, кэширование, асинхронная обработка, контроль пула соединений и снижение избыточной сериализации. Для системного уровня значимы управление памятью Linux, сокращение сетевого пути через eBPF/XDP или DPDK, настройка очередей и постоянная проверка влияния оптимизаций на p95/p99 latency. Оптимизация должна выполняться через измеримый цикл: формирование гипотезы, нагрузочное тестирование, проверка метрик CPU/RAM/latency/throughput/error rate, внедрение ограниченного изменения и повторная оценка. Такой подход снижает риск локальных улучшений, которые ухудшают устойчивость всей API-платформы.
Библиографический список
-
Stack Overflow. 2025 Developer Survey: Technology. URL: https://survey.stackoverflow.co/2025/technology (дата обращения: 23.06.2026).
-
Aluev A. Architectural Patterns for Building Secure High-Load APIs on Node.js Using REST, gRPC, and GraphQL // International Journal of Engineering in Computer Science. 2026. Vol. 8(1). P. 103-107. DOI: 10.33545/26633582.2026.v8.i1b.255.
-
Kovalevskyi K. Architectural approaches to building highly available api platforms for fintech applications // Cold Science. 2026. №25. P. 13-24.
-
Fauziah R., Surantha N. Evaluating Middleware Performance in the Transition from Monolithic to Microservices Architecture for Banking Applications // Electronics. 2026. Vol. 15(1). Article 221. DOI: 10.3390/electronics15010221.
-
Niswar M., Arisandy Safruddin R., Bustamin A., Aswad I. Performance evaluation of microservices communication with REST, GraphQL, and gRPC // International Journal of Electronics and Telecommunications. 2024. Vol. 70(2). P. 429-436. DOI: 10.24425/ijet.2024.149562.
-
Aluev A. Optimizing the performance of node.js services under high network load // Professional Bulletin: Information Technology and Security. 2026. №1. P. 3-9.
-
Kyriakou K.-I.D., Tselikas N.D. Complementing JavaScript in High-Performance Node.js and Web Applications with Rust and WebAssembly // Electronics. 2022. Vol. 11(19). Article 3217. DOI: 10.3390/electronics11193217.
-
Otkidach I. Operational optimization of memory management in Linux-based high-load service environments // Cold Science. 2026. №26. P. 28-39.
-
Otkidach I. Methods for reducing network latency in Linux systems // Universum: technical sciences: electronic scientific journal. 2026. № 5(146). P. 43-51.
-
Shahinfar F., Miano S., Panda A., Antichi G. Demystifying Performance of eBPF Network Applications // Proceedings of the ACM on Networking. 2025. Vol. 3. CoNEXT3. Article 16. DOI: 10.1145/3749216.
-
Castillon du Perron K., Lopez Pacheco D., Huet F. Understanding Delays in AF_XDP-based Applications // IEEE International Conference on Communications. 2024. DOI: 10.1109/ICC51166.2024.10622351.
-
Roilian M. Containerization and orchestration in IT infrastructure: DevOps practices, adaptability, and security // International Journal of Research and Scientific Innovation. 2025. Vol. 12(11). P. 2038-2045. DOI: 10.51244/IJRSI.2025.12110178.
-
Cloud Native Computing Foundation. Kubernetes Established as the De Facto Operating System for AI as Production Use Hits 82% in 2025 CNCF Annual Cloud Native Survey. 2026. URL: https://www.cncf.io/announcements/2026/01/20/kubernetes-established-as-the-de-facto-operating-system-for-ai-as-production-use-hits-82-in-2025-cncf-annual-cloud-native-survey/ (дата обращения: 23.06.2026).