Введение
Речь является основным средством коммуникации между людьми, однако её звуковая природа создает определённые трудности для анализа и обучения. В отличие от письменного текста или графического изображения, речь существует только в момент произнесения и не оставляет визуально воспринимаемых следов. Эта особенность становится значимой в ряде практических областей: при коррекции произношения у детей с нарушениями речи, при обучении иностранным языкам, в криминалистической идентификации личности по голосу, а также особую актуальность проблема восприятия речи приобретает для людей с нарушениями слуха – для них преобразование звучащей речи в визуальные образы становится важнейшим условием полноценного общения и доступа к информации.
Визуализация речи — это представление звукового сигнала в графическом виде. С помощью специальных программно-аппаратных средств речь отображается на экране в виде осциллограмм, спектрограмм или графиков частотных характеристик. Такое преобразование позволяет оценить параметры речи, которые трудно воспринять на слух: длительность звуков, их интенсивность, высоту тона и ритмическую структуру.
Первые попытки визуального представления речи были связаны с появлением аналоговых приборов – осциллографов и сонографов, позволявших наблюдать форму сигнала и его частотные компоненты в реальном времени. Эти устройства заложили основы спектрографического анализа, который впоследствии стал ключевым методом в лингвистических и коррекционных исследованиях. Параллельно, серьёзный импульс развитию речевых технологий в целом придал проект ARPA (Advanced Research Projects Agency), реализованный в США в 1971–1976 годах [1]. Хотя проект фокусировался на задачах распознавания слитной речи, разработанные в его рамках алгоритмы цифровой обработки сигналов (спектральный анализ, выделение формант, временная разметка) впоследствии нашли широкое применение и в системах визуализации. Несмотря на то, что массового внедрения эти разработки тогда не получили из-за высокой стоимости оборудования и сложности настройки, заложенные в рамках ARPA подходы к представлению речевого сигнала стали методологической базой для современных программно-аппаратных средств визуального отображения речи.
Дальнейшее развитие компьютерных технологий и методов цифровой обработки сигналов позволило визуализации речи выйти на новый уровень. Сегодня цифровые средства позволяют сочетать различные способы визуализации – от привычных осциллограмм до объёмных трёхмерных спектрограмм – и применять их в самых разных сферах.
1. Теоретические основы визуализации речи
1.1. Речь как физический процесс
Речь — это колебания воздушной среды, вызванные органами речи. Она имеет три основные характеристики: громкость (амплитуда), высоту (частота) и тембр (спектральный состав). Задача визуализации речи — сделать эти невидимые параметры видимыми.
1.2. Способы визуализации звука
Существует несколько способов графического представления речи, каждый из которых имеет свое назначение и область применения.
Осциллограмма — это зависимость амплитуды звука от времени. Проще говоря, форма звука. По горизонтальной оси откладывается время, по вертикальной — амплитуда. Осциллограмма позволяет определить длительность звуков и пауз, оценить ритмическую структуру речи и общую динамику громкости. Однако она не дает информации о частотном составе звука, поэтому по осциллограмме невозможно определить, какой именно звук был произнесен [2].
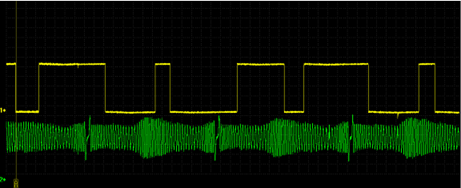
Рисунок 1. Осциллограмма
Спектрограмма показывает частотный состав звука во времени. По горизонтали — время, по вертикали — частота, цветом обозначена громкость. Это основной инструмент анализа речи: на ней видны форманты (области усиленных частичных тонов в спектре музыкальных звуков или звуков речи, по ним различают звуки), интонация, шумы [3].
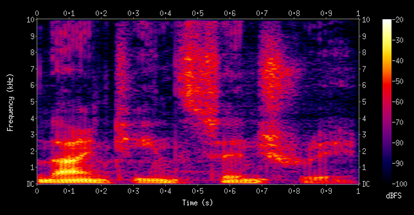
Рисунок 2. Спектрограмма мужского голоса
График основного тона (интонограмма) показывает изменение высоты голоса во времени. Используется для анализа интонации, мелодики речи, логических ударений.
Трехмерные визуализации — объемное изображение, где к частоте и времени добавляется ось громкости. Позволяет рассматривать звук как рельефную поверхность. Используется в научных исследованиях и современных обучающих программах.
1.3. Принцип работы программно-аппаратных средств
Аппаратная часть любой системы визуализации речи решает одну главную задачу: преобразовать акустические колебания в цифровой сигнал, пригодный для программной обработки.
Этот процесс включает три этапа:
Микрофон преобразует звуковые волны в аналоговый электрический сигнал.
Аналого-цифровой преобразователь (АЦП) измеряет этот сигнал тысячи раз в секунду и преобразует в двоичные коды. Специализированный контроллер или аудиоинтерфейс считывает эти коды и сохраняет их в памяти в виде массива чисел, который представляет собой цифровую осциллограмму речевого сигнала. Ключевые параметры АЦП: частота дискретизации (от 8–10 кГц для базовых задач до 22 кГц для детального формантного анализа) и разрядность (12–16 бит для стандартных применений, 16–24 бита для исследовательских и криминалистических систем) [4].
Полученный массив чисел передается в программную часть, где начинается его математическая обработка.
Программная обработка реализует методы, которые извлекают из массива чисел акустические параметры, необходимые для визуализации:
Быстрое преобразование Фурье (БПФ) раскладывает сложный звуковой сигнал на частоты. На его основе строятся спектрограммы — основной инструмент анализа речи, на котором видны форманты, интонационный контур и шумы [5].
Метод линейного предсказания (LPC) представляет речевой тракт в виде авторегрессионного фильтра — такой модели, где каждое следующее значение сигнала вычисляется как взвешенная сумма нескольких предыдущих значений. Программа находит коэффициенты этой суммы, которые отражают резонансные свойства речевого тракта. Из этих коэффициентов затем определяются форманты — частоты, которые речевой тракт усиливает наиболее сильно [6].
Вейвлет-анализ раскладывает сигнал на короткие волны разного масштаба, позволяя одновременно анализировать и частоты, и их точное время появления. В отличие от Фурье, он обеспечивает адаптивное разрешение, что повышает точность анализа нестационарных участков сигнала. На его основе строятся вейвлет-спектрограммы с высоким разрешением [5].
Алгоритмы выделения основного тона ищут в массиве повторяющиеся участки с использованием разностной функции и вычисляют период колебаний в диапазоне 70–450 Гц. На их основе строятся интонограммы – графики изменения высоты голоса во времени [7].
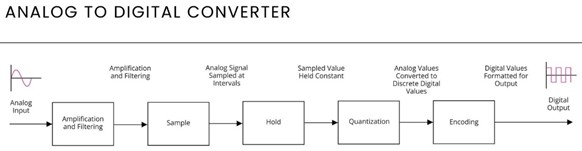
Рисунок 3. Блок-схема аналого-цифрового преобразования
После математической обработки полученные числовые параметры преобразуются в визуальные образы. Способ отображения зависит от назначения системы:
В исследовательских программах строятся точные графики (спектрограммы, интонограммы).
В коррекционных системах используется мультипликация – параметры речи управляют поведением игровых персонажей, создавая интуитивно понятную обратную связь.
В приложениях для обучения произношению форманты отображаются в виде точки на квадрате гласных.
В современных разработках визуализация интегрируется с видео и дополненной реальностью.
2. Классификация и обзор существующих систем
Все многообразие систем визуализации речи можно разделить на несколько групп в зависимости от назначения.
2.1. Системы для коррекции речи и слуха (логопедия, реабилитация, коммуникация)
Данная группа включает системы, предназначенные для работы с людьми, имеющими нарушения слуха и речи. Они применяются как в детской логопедии, так и при реабилитации взрослых пациентов после инсультов, черепно-мозговых травм и нейрохирургических операций. Главная особенность – визуальная обратная связь, позволяющая контролировать речь через зрительный канал.
«Видимая речь III» (входит в линейку IBM SpeechViewer, США) — классический сурдопедагогический комплекс, разработанный американской корпорацией IBM и адаптированный для использования в России. Предназначен для обучения произношению детей и взрослых с нарушениями слуха. Параметры речи (дыхание, наличие голоса, высота тона, громкость, длительность, спектр) преобразуются в игровые образы на экране, обеспечивая визуальную обратную связь. Программа включает 13 модулей. Эффективность «Видимой речи III» подтверждена в работе Е.В. Шевченко (2010). В исследовании на базе ДОУ № 311 (Новосибирск) с участием 26 дошкольников с нарушениями слуха было показано, что использование программы улучшает темп речи, громкость, высоту голоса и точность произношения, а также способствует развитию мотивации и самоконтроля [8].
Управление/интерфейс: Параметры речи преобразуются в игровые образы; 13 специализированных модулей.
Доступность: Адаптирована для России; требует лицензии IBM; распространяется через специализированные организации.
«Дельфа-142» (Россия, под рук. О.Е. Грибовой) — отечественная комплексная программа для коррекции устной и письменной речи. Звук отображается на экране в виде движущихся картинок, ориентируясь на которые ребенок контролирует произношение. Т.В. Шишова в своем исследовании с участием 100 старших дошкольников с дизартрией подтвердила эффективность тренажера: улучшение восприятия (до 87%), памяти, внимания, мотивации [9].
Управление/интерфейс: Звук отображается в виде движущихся картинок; комплексный подход к устной и письменной речи.
Доступность: Отечественная разработка; доступна через российских поставщиков логопедического оборудования.
Современные мобильные приложения для визуализации речи
В последние годы активно развиваются мобильные приложения, которые делают технологии визуализации речи доступными для широкого круга пользователей — логопедов, родителей и самих детей.
VowelViz (CompleteSpeech, США) — инновационное приложение для визуализации гласных, отображающее их произнесение на экране в режиме реального времени. Приложение использует квадрат гласных (vowel quadrilateral) — стандартную фонетическую схему, основанную на акустической теории речеобразования [10] и показывающую положение языка во рту при произнесении различных гласных. Визуальный маркер на экране отображает текущее положение произносимого звука, что позволяет обучающимся видеть, как движение языка влияет на звучание. Применяется в логопедии, при постановке произношения и изучении иностранных языков.
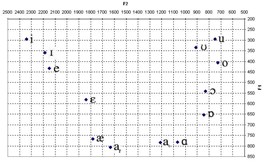
Рисунок 4. Акустический квадрат гласных: положение звуков определяется частотами первой (F1) и второй (F2) формант
2.2. Научные и исследовательские инструменты
Данная группа ориентирована на лингвистов, фонетистов и исследователей речи. Эти программы предоставляют точные инструменты акустического и мультимодального анализа и широко используются в научной среде.
Praat — это бесплатная кроссплатформенная программа с открытым исходным кодом, разработанная фонетиками Полом Берсмой и Дэвидом Винком в Амстердамском университете для научного анализа и синтеза речи [11]. Программа позволяет строить спектрограммы, извлекать частоту основного тона и проводить формантный анализ. Кроме того, Praat измеряет джиттер и шиммер – это показатели качества голоса: джиттер отражает нестабильность частоты колебаний голосовых связок (отклонения в периоде между колебаниями), а шиммер – нестабильность их амплитуды (перепады громкости от колебания к колебанию); оба параметра используются для диагностики нарушений голоса [12]. Программа также поддерживает сегментацию и разметку речи (создание многоуровневых аннотаций), позволяет синтезировать речь, выполнять статистическую обработку данных и создавать слуховые эксперименты.
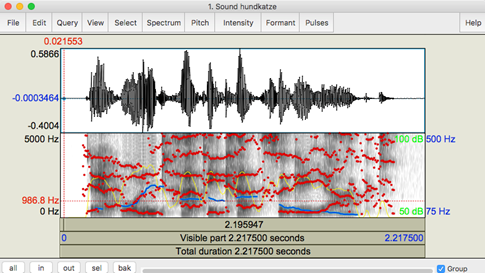
Рисунок 5. Осциллограммы и спектрограмма в Praat
ELAN (EUDICO Linguistic Annotator) — это бесплатная кроссплатформенная программа, разработанная Институтом психолингвистики Макса Планка (Нидерланды) для мультимодального анализа аудио- и видеозаписей. Программа предназначена для детальной разметки, когда необходимо одновременно отмечать речь, жесты, мимику, перевод и любые другие данные, привязанные ко времени. ELAN используется лингвистами для изучения языков жестов, антропологами для анализа поведения, исследователями для документации редких языков. Возможности программы включают создание неограниченного числа иерархических слоев аннотаций (фонетические транскрипции, морфологическая разметка, переводы, комментарии), привязку к временным меткам, совместимость с Praat, импорт и экспорт данных. Программа доступна бесплатно для Windows, Mac и Linux [12].
Speech Analyzer — это бесплатная программа для Windows, разработанная SIL International (США) для акустического анализа речи. Она предназначена для лингвистов, изучающих звуки, акценты и особенности произношения, а также для этномузыкологов, анализирующих народные песни и музыкальные традиции. Возможности программы включают спектрографический анализ, измерение частоты основного тона и длительности звуков, формантный анализ [13].
2.3. Криминалистические системы и системы безопасности
Данная группа предназначена для экспертных подразделений правоохранительных органов и решает задачи идентификации личности по голосу, анализа подлинности фонограмм и фоноскопической экспертизы.
«ИКАР Лаб II+» (Центр речевых технологий, Россия) — это программно-аппаратный комплекс для криминалистического анализа фонограмм, предназначенный для идентификации личности по голосу, проверки подлинности записей и очистки звука от шумов. Возможности программы включают спектральный анализ на основе быстрого преобразования Фурье (БПФ), сравнение формант и частоты основного тона, а также шумоочистку. Программное обеспечение является проприетарным и применяется в экспертно-криминалистической практике [5].
«Фон-NI» (МГТУ им. Баумана, Россия) — исследовательский прототип аппаратно-программного комплекса для криминалистического анализа фонограмм, разработанный на кафедре «Информационная безопасность» под руководством Ю.Г. Горшкова. В состав комплекса входит модуль сбора данных NI PXI–4461 (National Instruments, США) и специализированное программное обеспечение WaveView–4, реализующее многоуровневый вейвлет-анализ речевых сигналов. Программа строит вейвлет-сонограммы с высоким частотно-временным разрешением, позволяющие увидеть тонкую структуру гласных звуков [5]. Комплекс подготовлен для проведения сертификационных испытаний на соответствие международным требованиям.
2.4. Аппаратные решения (чипы и модули)
Данная группа представляет собой специализированные микросхемы и готовые модули, которые встраиваются непосредственно в устройства — роботов, игрушки, бытовую технику, системы «умного дома». Они берут на себя функцию распознавания речи, освобождая основное устройство от сложных вычислений. Данные чипы используются в портативных устройствах для отображения параметров речи (громкость, высота тона) на светодиодных индикаторах или экранах, обеспечивая визуальную обратную связь в реальном времени.
Voice Direct™ 364 (Sensory Inc., США) — промышленный чип для распознавания голосовых команд.
Тип распознавания: Дикторозависимое — требует предварительного обучения голосу конкретного пользователя.
Количество команд: До 60.
Гибкость настройки: Команды сохраняются во внешнюю память в виде образов размером 128 байт; изменение списка команд требует перепрограммирования.
Архитектура: Требует внешней памяти для хранения образов команд; сравнение происходит в нейросетевом модуле.
Точность распознавания: Обеспечивает надёжное распознавание небольшого числа предварительно обученных команд в условиях контролируемой акустической среды [14].
Область применения: Устройства, роботы, игрушки.
Удобство развёртывания: Требует этапа обучения для каждого нового пользователя – подходит для персонализированных устройств.
LD3320 (ICRoute, Китай) — промышленный чип для распознавания голосовых команд.
Тип распознавания: Дикторонезависимое — работает с любым голосом без предварительной настройки.
Количество команд: До 50.
Гибкость настройки: Список команд можно менять прямо в процессе работы.
Архитектура: Все необходимые компоненты интегрированы в один кристалл (процессор распознавания, АЦП, ЦАП, вход для микрофона, выход для динамика); внешняя память не требуется.
Точность распознавания: Средняя точность распознавания около 90% по результатам тестирования в системе умного дома [15].
Область применения: Роботы, игрушки, системы умного дома, встраиваемая электроника.
Удобство развёртывания: Подходит для массовых продуктов и систем с множественными пользователями.
2.5. Современные интеграционные разработки
Данная группа включает системы, объединяющие анализ звука и видео для создания новых возможностей обработки речи – реконструкции артикуляции по голосу, биометрической идентификации, аватаров.
Бимодальная реконструкция контура рта по голосу — это исследовательская разработка Университета ИТМО (Россия) под руководством А.Л. Олейника, предназначенная для восстановления изображения губ по звучащей речи. Метод работает следующим образом: программа анализирует речевой сигнал, выделяет из него ключевые характеристики произнесенных звуков и на их основе определяет положение губ, восстанавливая координаты 20 опорных точек, описывающих контур рта. По сути, по голосу восстанавливается артикуляция – то, как должен двигаться рот при произнесении тех или иных звуков. Эксперименты проводились на записях 43 дикторов и показали высокую точность: ошибка восстановления контура рта составила всего 2–4% от ширины рта, при этом для обучения системы достаточно всего 12 минут речи. Технология может применяться для создания управляемых голосом аватаров, в биометрических системах идентификации по лицу и голосу, для защиты от подделок, а также в обучении произношению, где она может обеспечивать визуальную обратную связь. На данный момент это результаты исследований, но в перспективе возможна реализация в прикладных разработках [16].
Scribbling Speech — экспериментальный проект, представляющий собой бакалаврскую работу Синьюэ Янг (Xinyue Yang) под руководством К. Цвика (C. Zwick). Проект направлен на создание визуальных миров в реальном времени на основе речевого ввода. Система использует комбинацию технологий: Google Speech API (набор готовых функций для распознавания речи), Google Natural Language API (инструмент для анализа синтаксиса и смысла текста) и набор данных Quickdraw от Google, содержащий миллиарды схематичных рисунков, созданных пользователями по всему миру. Рекуррентные нейросети генерируют изображения на основе выделенных из речи ключевых слов (существительных и пространственных предлогов), определяя объекты и их взаимное расположение в трехмерном виртуальном пространстве. Пользователь также может управлять виртуальной камерой голосовыми командами («посмотри налево», «подойди к дому»). Система поддерживает несколько языков (английский, китайский, французский, немецкий) и демонстрирует перспективное направление визуализации речи, где результатом становятся не абстрактные графики, а интуитивно понятные сюжетные анимации [17].
Hand Talk (Бразилия) — система автоматического перевода речи и текста в бразильский язык жестов (LIBRAS) и американский (ASL). Комплекс включает два основных продукта: веб-переводчик, делающий интернет-ресурсы доступными для глухих пользователей путем вставки кнопки активации перевода, и мобильное приложение, принимающее на вход текст или аудиосигнал и автоматически генерирующее жестовый перевод. Система использует технологии распознавания речи и обработки естественного языка для преобразования входных данных в анимированные жесты, что обеспечивает доступность цифровой информации для людей с нарушениями слуха. Разработчики позиционируют Hand Talk как инструмент, дополняющий работу сурдопереводчиков и расширяющий возможности инклюзивной коммуникации в цифровой среде [18].
В дополнение к системам, визуализирующим акустические параметры речи (громкость, частоту, спектр), развивается направление семантической визуализации, где результатом преобразования становится не график, а изображение, соответствующее смыслу высказывания. В таких системах речевой сигнал сначала распознаётся в текст, затем с помощью методов анализа естественного языка (это алгоритмы, которые выделяют из текста ключевые слова, связи между ними и эмоциональную окраску) формируется смысловое описание, на основе которого генеративная нейросеть создаёт визуальный образ — например, иллюстрацию к произнесённой фразе. Примером служит система Speech Illustrator, преобразующая речь в изображения в реальном времени с поддержкой более 90 языков и возможностью выбора художественного стиля. Такие решения особенно значимы для повышения доступности информации: люди с нарушениями слуха получают возможность воспринимать аудиоконтент (лекции, подкасты, голосовые сообщения) через визуальные образы, что снижает зависимость от слухового канала и расширяет возможности инклюзивного обучения и коммуникации [19].
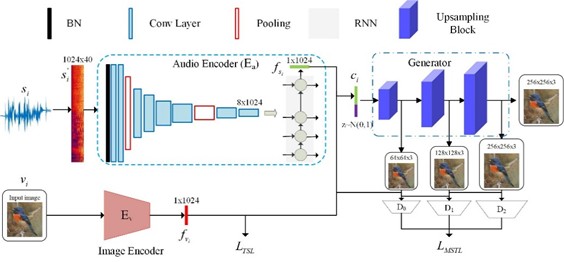
Рисунок 6. Рисунок архитектуры системы прямого преобразования речи в изображение
2.6. Области применения рассмотренных систем
Рассмотренные программно-аппаратные средства визуализации речи находят применение в различных направлениях: коррекции и реабилитации речи (логопедия, сурдопедагогика), научных исследованиях (акустический и мультимодальный анализ), криминалистической экспертизе (идентификация личности, проверка подлинности фонограмм) и прикладных решениях (голосовое управление, биометрия, виртуальные аватары). Эволюция технологий от узкоспециализированных инструментов к массовым продуктам расширяет возможности использования визуализации речи в медицине, образовании, безопасности и повседневной коммуникации.
3. Перспективы развития программно-аппаратных средств визуализации речи
На основе анализа существующих систем можно выделить несколько ключевых направлений дальнейшего развития технологий визуализации речи.
Миниатюризация и мобильность. Современные аппаратные решения (чипы LD3320) и мобильные приложения (VowelViz) позволяют встраивать визуализацию в компактные устройства. В перспективе технологии станут доступными в умных часах, AR-очках и слуховых аппаратах. Параллельно будет развиваться персонализация интерфейсов и применение игровых механик для повышения мотивации пользователей и удобства взаимодействия с системой.
Нейросетевые технологии. Искусственный интеллект дополнит классические методы (БПФ, LPC, вейвлет-анализ), автоматизируя выделение параметров и улучшая качество визуализации: повышая четкость спектрограмм, восстанавливая сигнал из шума и автоматически подсвечивая значимые зоны.
Совместный анализ голоса и изображения для повышения точности. Исследования ИТМО (А.Л. Олейник) демонстрируют перспективность восстановления контура губ по голосу для создания аватаров и биометрической идентификации. Также набирают популярность автоматические переводчики на жестовые языки (например, Hand Talk), и в перспективе они появятся для всех основных языков, стирая коммуникационные барьеры. Параллельно развивается направление семантической визуализации, где смысл речи преобразуется в изображения: система распознаёт произнесённые слова, выделяет ключевые понятия и с помощью генеративной нейросети создаёт иллюстрацию, соответствующую содержанию высказывания. Такие решения особенно важны для людей с нарушениями слуха, позволяя воспринимать аудиоконтент через визуальные образы. В перспективе эта технология может быть интегрирована с дополненной реальностью: пользователь сможет видеть «всплывающие» иллюстрации к произносимой речи непосредственно в поле зрения (через AR-очки или смартфон), что обеспечит естественное восприятие информации в реальной среде. Вейвлет-технологии (комплекс «Фон-NI») обеспечат более детальную частотно-временную структуру для высокоточной фоноскопической экспертизы.
Трехмерная визуализация. Развитие объемных спектрограмм ведет к появлению интерактивных инструментов, где звук можно вращать, масштабировать и рассматривать с разных сторон. В сочетании с VR это позволяет исследователям и студентам «погружаться» внутрь звука для детального анализа. В обучении и реабилитации трехмерная визуализация делает обратную связь более интуитивной — пациенты с нарушениями слуха воспринимают звуки как объемные объекты в пространстве. В игровых проектах вроде Scribbling Speech пользователь может рассматривать созданные по голосу трехмерные сцены с разных сторон. В перспективе такие технологии позволят управлять виртуальными мирами голосом, создавать новые способы взаимодействия со звуком в образовании, медицине и развлекательных приложениях.
Развитие технологий движется в сторону миниатюризации, использования нейросетей и интеграции с другими модальностями, делая визуальную обратную связь неотъемлемой частью повседневной коммуникации, образования и медицины.
4. Заключение
В работе проведён систематический обзор программно-аппаратных средств визуализации речи, классифицированных по функциональному назначению и техническому исполнению. Установлено, что современные технологии визуального отображения речи охватывают широкий спектр задач.
Сравнение показало, что, несмотря на различия в архитектуре и методах обработки сигнала, все рассмотренные системы базируются на единых физических принципах: преобразовании акустических колебаний в цифровой сигнал с последующим извлечением информативных параметров (амплитуды, частоты, спектрального состава) и их графической интерпретацией.
Результаты работы подтверждают, что визуализация речи трансформируется из узкоспециализированного инструмента в универсальную технологию, востребованную в медицине, образовании, безопасности и повседневной коммуникации — от логопедии до автоматических переводчиков на жестовые языки. Дальнейшее развитие связано с созданием систем, объединяющих анализ звука и изображения, а также с использованием технологий виртуальной и дополненной реальности.
Библиографический список
- Анатолий Чекмарев. Речевые технологии — проблемы и перспективы. Компьютерра, (49), 1997.
- В. П. Дьяконов. Современная осциллография и осциллографы. Библиотека инженера. СОЛОН-Пресс, М., 2013.
- В. Л. Столбов, М. Б. Иванов. Анализ и модели речевых сигналов. Университет ИТМО, СПб., 2024. Учебное пособие.
- Вольфганг Райс. Как работают аналогово-цифровые преобразователи и что можно узнать из спецификации на АЦП? Компоненты и технологии, 3:116–121, 2005. URL: https://cyberleninka.ru/article/n/kak-rabotayut-analogovo-tsifrovye-preobrazovateli-i-chto-mozhno-uznat-iz-spetsifikatsii-na-atsp/viewer.
- А. М. Горшков, Ю. Г. Каиндин. Инструментальные средства фоноскопической экспертизы аудиозаписей. Вестник МГТУ им. Н.Э. Баумана. Серия «Приборостроение», 2:35–47, 2012. URL: https://cyberleninka.ru/article/n/instrumentalnye-sredstva-fonoskopicheskoy-ekspertizy-audiozapisey/viewer.
- К. Ч. Гуртуева, И. А. Бжихатлов. Аналитический обзор и классификация методов выделения признаков акустического сигнала в речевых системах. Известия Кабардино-Балкарского научного центра РАН, 105(1):41–58, 2022. URL: https://cyberleninka.ru/article/n/analiticheskiy-obzor-i-klassifikatsiya-metodov-vydeleniya-priznakov-akusticheskogo-signala-v-rechevyh-sistemah/viewer, doi:10.35330/1991-6639-2022-1-105-41-58.
- Д. Н. Первушин, Е. А. Лавров. Алгоритм выделения основного тона и детектирования тон/не тон по минимумам разностной функции на участке минимального периода. Математические структуры и моделирование, pages 24–27, 2011. URL: https://cyberleninka.ru/article/n/algoritm-vydeleniya-osnovnogo-tona-i-detektirovaniya-ton-ne-ton-po-minimumam-raznostnoy-funktsii-na-uchastke-minimalnogo-perioda/viewer.
- Е. В. Шевченко. Коррекция произносительной стороны речи у детей дошкольного возраста с нарушением слуха с помощью компьютерной программы «Видимая речь iii». Мир науки, культуры, образования, 24(5):176–178, 2010. URL: https://cyberleninka.ru/article/n/korrektsiya-proiznositelnoy-storony-rechi-u-detey-doshkolnogo-vozrasta-s-narusheniem-sluha-s-pomoschyu-kompyuternoy-programmy-vidimaya/viewer.
- Т. В. Шишова. Использование логопедического тренажера «Дельфа-142» при коррекции нарушений речи у старших дошкольников с дизартрией. Образование и наука, 7(86):118–125, 2011. URL: https://cyberleninka.ru/article/n/ispolzovanie-logopedicheskogo-trenazhera-delfa-142-pri-korrektsii-narusheniy-rechi-u-starshih-doshkolnikov-s-dizartriey/viewer.
- Г. Фант. Акустическая теория речеобразования. Наука, М., 1964.
- Paul Boersma and David Weenink. Praat: doing phonetics by computer. Software, 2025. Version 6.4. URL: http://www.praat.org/.
- О. В. Гончарова. Цифровые исследования звучащей речи: история, методология, современные инструменты. Филологические науки. Вопросы теории и практики, 18(8), 2025. URL: https://cyberleninka.ru/article/n/tsifrovye-issledovaniya-zvuchaschey-rechi-istoriya-metodologiya-sovremennye-instrumenty/viewer.
- Р. Э. Кульшарипова, Ч. Вэйвэй. Акустический анализ русской речи китайцев с помощью программы speech analyzer. Ученые записки Казанского университета. Серия Гуманитарные науки, 2014. URL: https://cyberleninka.ru/article/n/akusticheskiy-analiz-russkoy-rechi-kitaytsev-s-pomoschyu-programmy-speech-analyzer/viewer.
- М. Т. Мырадов, С. Н. Назарова. Современные технологии распознавания речи. Наука и мировоззрение, 1:1–5, 2023.
- Lei Wang. Design of speech recognition system based on ld3320 chip. In Proceedings of the 2016 3rd International Conference on Materials Engineering, Manufacturing Technology and Control (ICMEMTC-16). Atlantis Press, 2016. doi:10.2991/icmemtc-16.2016.33.
- А. Л. Олейник. Обработка и анализ звуковой и визуальной составляющих речи на основе проекционных методов. Научно-технический вестник информационных технологий, механики и оптики, 18(2):243–254, 2018. URL: https://cyberleninka.ru/article/n/obrabotka-i-analiz-zvukovoy-i-vizualnoy-sostavlyayuschih-rechi-na-osnove-proektsionnyh-metodov/viewer.
- Xinyue Yang. Scribbling speech: Turn real time free speech into animated drawings. Experiments with Google, 2018. URL: https://experiments.withgoogle.com/scribbling-speech.
- М. А. Булганбаева, А. Б. Булганбаев. Исследование языка жеста для цифрового перевода: обзорный анализ. Universum: технические науки, 2022. URL: https://cyberleninka.ru/article/n/issledovanie-yazyka-zhesta-dlya-tsifrovogo-perevoda-obzornyy-analiz/viewer.
- Speech Illustrator. Speech illustrator: Real-time image generation from speech. Website, 2026. URL: https://speechillustrator.com/.