

Компьютерная корпусная лингвистика развивает компьютерные методы анализа и обработки языков, развитие получило в середине двадцатого века, с развитие вычислительной техники и программного обеспечения. Наибольшое развитие получили английский язык и европейские языки, в нашей стране развиваются русский язык и в том числе, языки народов Российской Федерации, таких как башкирский [1], дагестанские языки [2], татарский и другие.
Якутский язык относится к языкам агглютинативного типа, то есть к языкам, словообразование которых происходить присоединением аффиксов, к таким языкам относятся все тюркские языки. Для развития методов компьютерной обработки якутского языка был создан газетный корпус, объем которого составляет более 12 млн. словоупотреблений, количество словоформ более 350 тыс. [3-4].
Для определения языка текста были применены методы словаря [5], метод биграмм [6], с помощью словаря газетного корпуса, триграмм [8]. Словарный метод обладает низким качеством определения языка, так как существует большая зависимость от словаря, метод биграмм является более точным, чем словарный метод, но при определении языков принадлежащих к одной группе показывает большую вероятность неверного определения. Метод триграмм обладает более высокой вероятностью точного определения языка, но есть необходимость в выборе и составлении словаря триграмм [9].
Обычно в ранних работах применялся порог в 50%, но с увеличением базы данных триграмм встал вопрос об определении порога триграмм, так как это влияет на точность определения языка.
Введем понятия вероятность определения слова, которая зависит от того, сколько триграмм в слове относятся к якутскому языку. Если слово относится к словарю, из которого были собраны триграммы, то слово имеет 100% триграмм с происхождением из якутского языка.
Для исследования были выбраны тексты на русском и якутском языке, в равном количестве, то 100 текстов с обоих языков. Каждый текст был обработан определителем языка, был выведен процент вероятности определения слова как якутского, подсчитано количество слов соответствующий вероятности определения слов. По полученным результатам, выведены графики на рисунке 1.
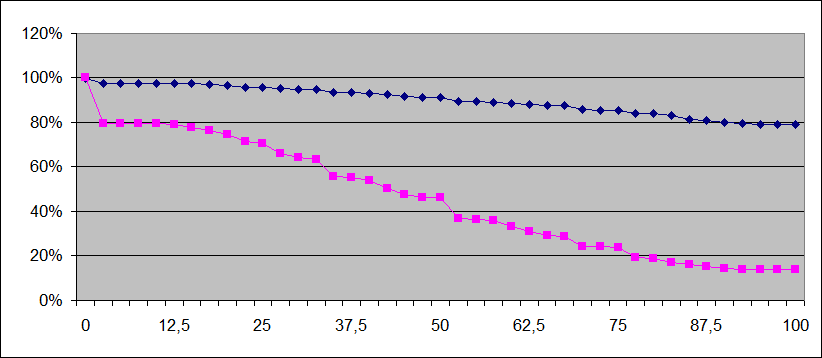
Рис.1 Зависимость порога определения от вероятности определения слова
На рисунке 1 показана зависимость определения языка текста от вероятности определения слов (♦ – якутский язык, ■ – русский язык).
Если возьмем порог 25%, то вероятность определения текста как якутского составить 97% в случае текста на якутском языке и 70% в случае текста на русском языке. Если порог будет 50%, то вероятности будут соответственно 90% и 40%, в случае порога 75%, вероятности составят около 85% и 25%. В случае порога 100%, вероятности составят 79% и 14%.
Максимальная разница между двумя вероятности равняется 66% и лежит в промежутке между 80% и 85%. Оптимальным является порог значений 80%.
В тексте на якутском языке встречаются заимствованные слова, написанные по правилам русского языка, данные слова снижают вероятность определения якутского языка.
Заключение
Для программного определителя якутского языка с помощью триграмм оптимальным порогом является значение 80%. Имеется зависимость от размера базы триграмм, но при достаточно большом размере данная зависимость становится незначительной и зависит уже от фонетизации заимствованных слов.
Библиографический список
- Сиразитдинов З.А. Корпусные проекты лаборатории лингвистики и информационных технологий ИИЯЛ УНЦ РАН/Известия Уфимского научного центра РАН. 2013. № 4. С. 104-111.
- Магомедов М.И. Создание и развитие корпусных ресурсов по литературным языкам народов Дагестана // Известия Кабардино-Балкарского научного центра РАН – №3 – 2012 – с.200-207
- Леонтьев Н.А. Национальный корпус Интернет-сайтов газет на якутском языке // Журнал научных и прикладных исследований – 2014 – №4 – с.53-54
- Leontiev N.A. The newspaper corpus of the yakut language // Proceeding of the International Conference “Turkic Languages Prosessing: TurkLang-2015”– 2015 – p.233-235
- Леонтьев Н.А. Словарное определение якутского языка в текстовом сообщении // Научная перспектива – 2014 – №2– с.97-98
- Леонтьев Н.А. Идентификация языка текстового сообщения с помощью газетного корпуса якутского языка // Universum: технические науки – 2014 – № 8(9) –с.2
- Леонтьев Н.А. Распознавание языка текстовых сообщений с помощью биграмм на материалах якутского языка // Современное состояние естественных и технических наук – 2014 – №XIV – с.88-91
- Леонтьев Н.А., Слепцов И.А. Идентификация текстового документа с помощью триграмм на материалах якутского языка // Вестник Северо-Восточного федерального университета им. М.К. Аммосова – 2015 – №4 (48) – с.45-50
- Леонтьев Н.А. Вопрос выбора словаря триграмм для автоматической идентификации якутского языка // Современные научные исследования и инновации – 2014 – №12-1 (44) –с.66-68
Количество просмотров публикации: Please wait