

Анализ процессов (process mining) – это относительно новая дисциплина. Основная идея анализа процессов – это выявлять, отслеживать и улучшать реальные (не придуманные) процессы, извлекая знания из журналов событий. [1] Системы логгирования широко применяются в современных информационных системах, как правило, с целью профилактики возникших ошибок и исключений в ходе работы системы.
Методы Process Mining применяются к журналам событий информационных систем. В них отражается реальное выполнение бизнес-процессов через взаимодействие их исполнителей с информационными системами. Применение к ним методов Process Mining позволяет автоматически построить модели бизнес-процессов. Построенные таким образом модели бизнес-процессов отражают реальность и доступны для восприятия и анализа человеком. На основании их анализа могут приниматься решения о внесении изменений в бизнес-процессы и/или о модернизации и настройке информационной системы.
Для построения модели, журнал событий должен иметь как минимум четыре поля[1]:
-
Событие(activity) – непосредственно какое-то событие, действие, например, авторизация, просмотр страницы;
-
Время регистрации события (Timestapm) – время начала события;
-
Идентификатор последовательности событий (Case id) – таким образом идентифицируется последовательность действий. В веб-ресурсах в этой роли может выступать идентификатор сессии или ip-адрес;
-
Ресурс(Resource) – под ресурсом подразумевается исполнитель, или инициатор активности, это может быть, как пользователь, так и внешняя информационная система;
Если действия в информационной системе логгируются, то формирование подобного журнала не представляет из себя сложную задачу. Многие системы, например, как moodle, позволяют выгружать журналы событий через административный интерфейс.
Чтобы избежать эффекта паралича анализа требуется осуществить качественную постановку задачи, поскольку работа с данными не имеет однозначных алгоритмов и может быть реализована множественными путями. Об этом же говорят и положения манифеста, написанного IEEE Task Force on Process Mining [2].
Для примера рассмотрим веб-ресурс на основе платформы moodle (https://moodle.org) для образовательных ресурсов. На данном сайте есть доступ к демоверсии этой системы – http://school.demo.moodle.net, заполненной некоторыми курсами и тестовыми пользователями. Постараемся произвести оценку поведения пользователей в рамках демо версии.
Для построения модели будут использованы два инструмента: основной [1] инструмент – ProM (http://www.promtools.org/doku.php) и, коммерческий – Disco (http://fluxicon.com/disco) для сравнения.
Чтобы получить журналы действий из административного интерфейса moodle необходимо авторизоваться под пользователем с необходимыми правами, и в левом меню выбрать администрирование (Site administration), затем отчеты (reports), затем журнал событий (logs). Выгрузить журнал возможно в нескольких форматах, но в используемых инструментах удобнее всего будет работать с csv файлами. Выгружаемый файл будет иметь вид как в таблице 1.
Таблица 1. Формат выгружаемых данных из системы moodle
| Time | User full name | Affected user | Event context | Component | Event name | Description | Origin | IP address |
| 16 Mar, 00:44 | - | - | Page: Choose a role | Page | Course module viewed | The user with id ’0′ viewed the ‘page’ activity with course module id ’44′. | web | 125.164.150.177 |
Можно увидеть, что в файле отсутствует поле «идентификатор последовательности» (case id), его заменит поле «ip address». Стоит отметить, что в реальных ситуациях ip – адрес не может быть надежным идентификатором сессии, так как, например, с одного компьютера могут заходить разные пользователи, хотя и такие случаи возможно рассматривать как единую последовательность. Так же в журнале выводится дата в формате, настроенном в системе, и его придется преобразовывать в более удобный для анализа вид, например, «день.месяц.год часы:минуты» .
В «moodle» под событием (столбец «event name») понимаются действия более абстрактного уровня, и всего насчитывают около нескольких десятков штук, поэтому совместим столбцы «event name» и «event context» в столбец «event» для большей наглядности.
В результате преобразований получим журнал в виде таблицы 2.
Таблица 2. Формат преобразованного журнала событий
| Date | User full name | Affected user | Event context | Component | Event name | Description | Origin | IP address | event |
| 16.03.2014 00:00 | Guest user | - | System | System | User has logged in | The user with id ’1′ has logged in. | web | 24.20.108.104 | User has logged in — System |
Важно отметить, что в реальных журналах событий проблемы могут носить более серьезный характер: шумы, пропущенные действия подробнее рассматривается в [1]. Для примера предполагается, что все полученные журналы событий полностью достоверны.
При анализе журналов событий, зачастую, получаемые модели слабо структурированы и не имеют отличительных особенностей (Рис.1), их называют спагетти подобными(spaghetti-like) моделями [1]. Этот случай не исключение, на рисунке 1 показана модель, полученная из журнала событий за один год.
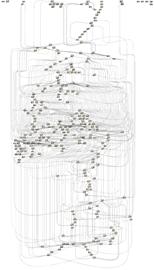
Рис.1 Спагетти-подобная(spaghetti-like) модель
Для таких моделей рекомендуется использовать Fuzzy miner алгоритм. Алгоритм использует показатели значимости (significance) / корреляции (correlation) в интерактивном режиме упрощая модели процесса до требуемого уровня абстракции. В отличии от эвристического подхода, он может удалить менее важные события (или скрыть их в кластеры), если их сотни. Нечеткая модель не может быть преобразованы в другие типы моделей, но можно использовать её, чтобы анимировать журнал событий на созданной модели, чтобы «почувствовать» поведение процесса [3], поэтому и был сделан выбор в пользу инструментов Disco и ProM, и алгоритма «нечеткого поиска» в частности. Более подробное рассмотрение алгоритма в задачи не входило, подробнее можно изучить в [4].
Для наглядности и простоты, бралась часть журнала за сутки, в которой содержалось 24 последовательности событий, 105 событий, с 33 классами (видами) событий и 7 исполнителями, так как пробная версия позволяет рассматривать только примерно 100 событий, но этого будет достаточно.
Сначала будет рассматриваться модель, полученная с помощью инструмента Disco.
Рис. 2 Разметка журнала
Disco позволяет разметить (Рис. 2) csv документ и отметить, какие колонки отвечают за такие данные как событие, ресурс, идентификатор последовательности, временная метка и другие данные, а также позволяет не учитывать колонки при рассмотрении.
На рис. 3 показана полная модель поведения, включающая 100% событий и переходов. На ней прямоугольники – события, стрелки – переходы. Более темные прямоугольники и более толстые стрелки обозначают более частые повторения. Цифры – количество действий. Зеленая точка – псевдо-событие начала, красная псевдо-событие конца. Зеленные пунктирные линии – переходы «входа». Красные пунктирные – переходы «выхода»
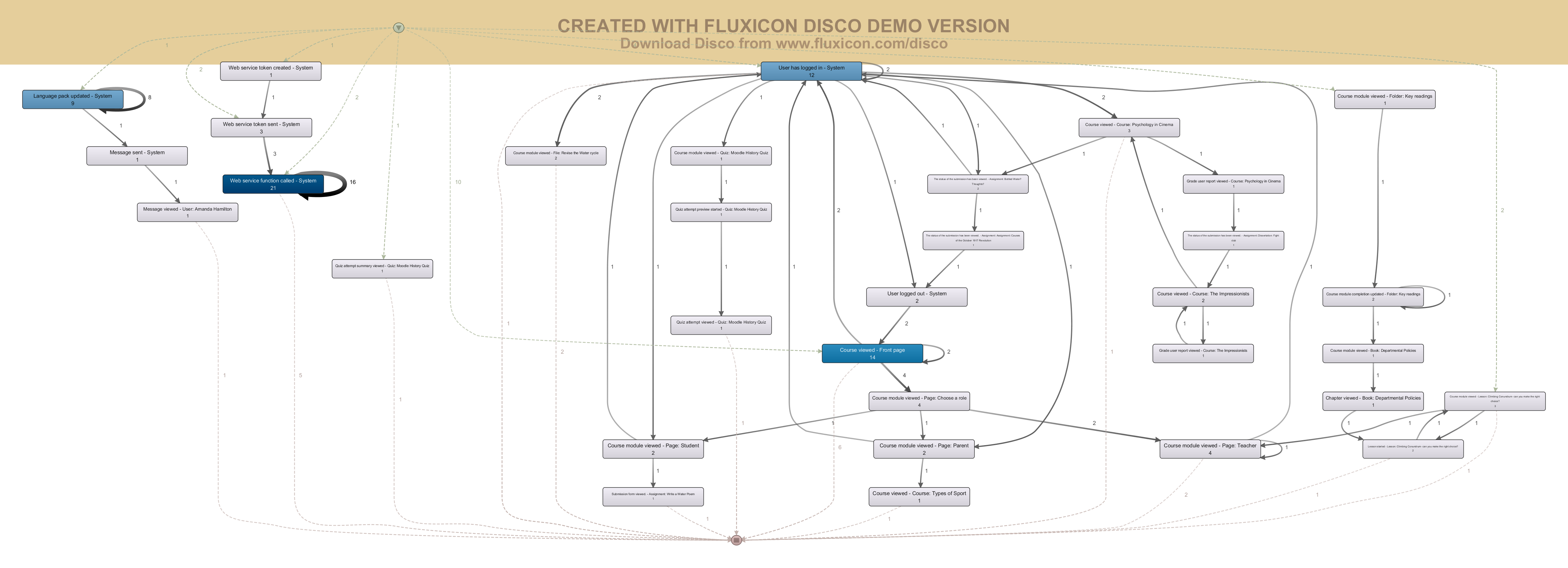
Рис. 3 Полная модель поведения
Уже из рассмотрения этой модели можно предположить, что пользователей интересуют локализация, просмотр возможностей курсов со стороны авторизованных пользователей и ролевая модель. В модели можно увидеть такое поведение как «Web service function called – System» – это вызов сервисных функций таких как: получение информации о сайте, календарь, или личные сообщения. Наличие этого события говорит о том, что первоначальное предположение о полной достоверности и полноте данных не совсем верно, так как не вся информация «лежит» на поверхности. Но возможности, скрывающиеся под вызовом сервисных функций зачастую есть во всех аналогичных типах веб-ресурсов и не требуют дополнительного внимания при рассмотрении и анализе.
Одним из основных инструментов упрощения модели и отображения более высокого уровня абстракции модели является уменьшение количества отображаемых событий и переходов. На рисунках 4 и 5 отображен результат применения этих инструментов: отображены только 30% действий и 40% переходов.
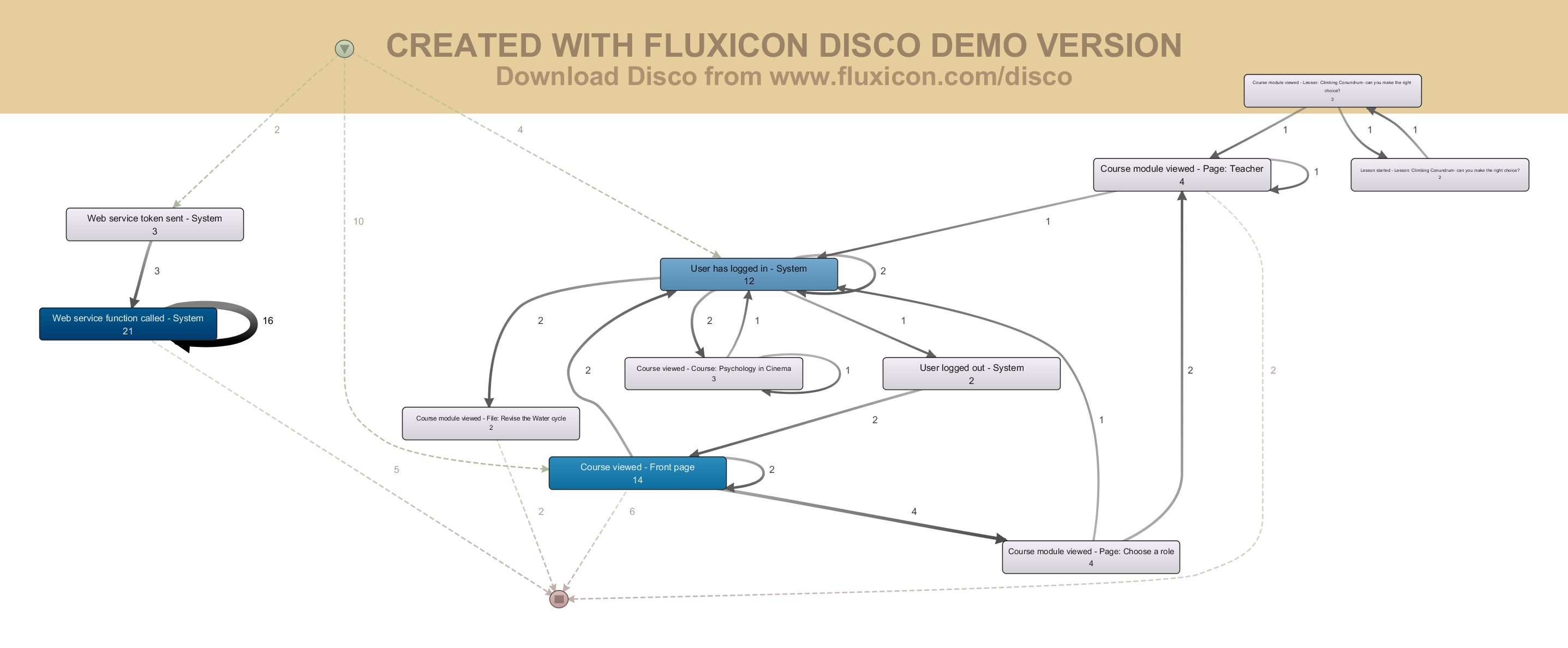
Рис. 4 модель, показывающая 30% действия и 40% переходов
Тут можно сказать, что частично предположения об интересах пользователя подтверждаются, то есть типичный пользователь в основном осматривает возможности ролевой системы, курсы. Вызов сервисных функций не убирается из модели, так как из-за частого повторения события его значимость становится выше [4].
Также, в Disco есть возможность отображения показателей производительности. Примером может служить среднее время перехода от одного действия к другому, однако в текущем контексте веб-ресурса необходимо трактовать как время, проведенное на странице/сервисе отображаемого в модели в виде прямоугольника (Рис.5). Видно, что пользователь провел больше времени на главной странице, странице выбора роли так как на этих страница отображена основная вводная информация.
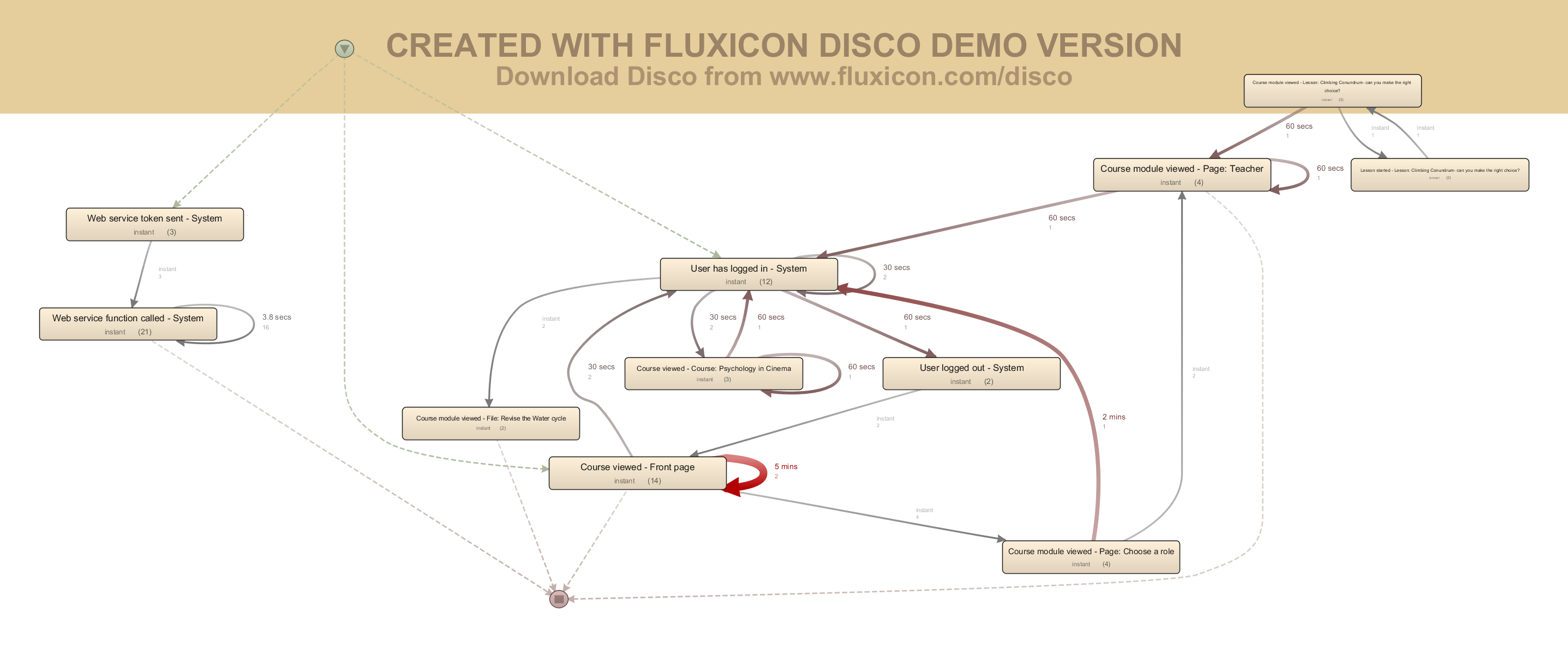
Рис. 5 модель, показывающая 30% действия и 40% переходов, так же, отображающая показатели производительности
Disco позволяет создавать различные фильтры, по времени, атрибутам и т.п.
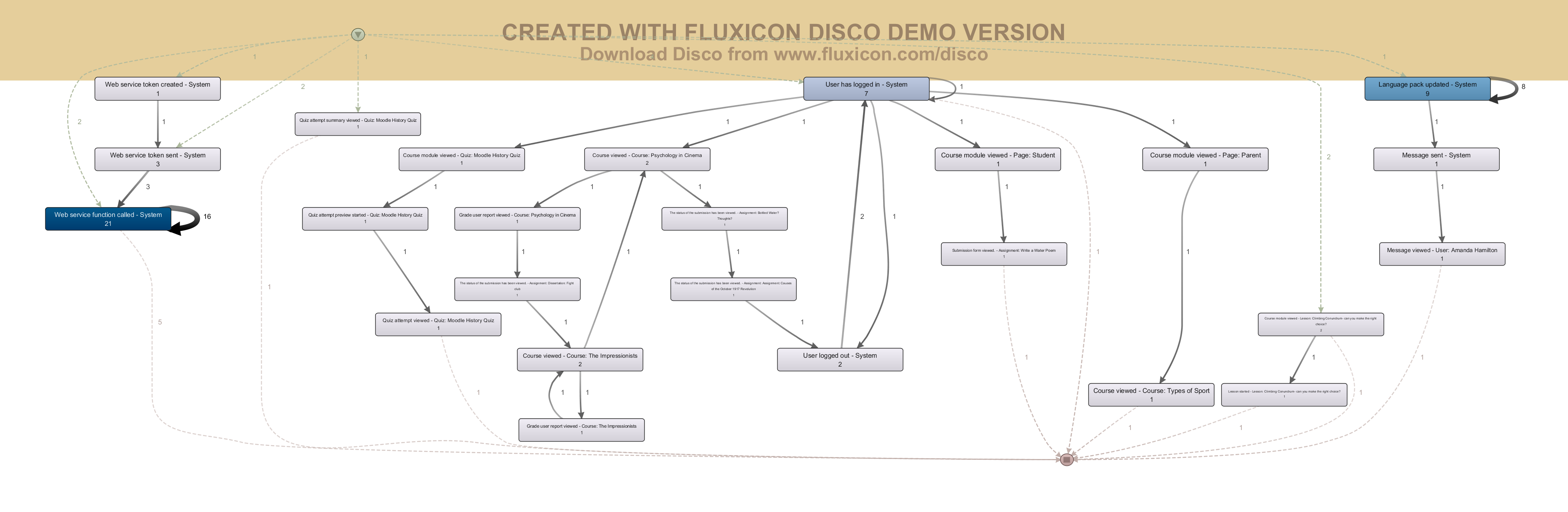
Рис. 6 отфильтрованная модель, показывающая действия только авторизованных пользователей
На рисунке 6 показан фильтр только по авторизованным пользователям, то есть отображены только те действия, которые выполнялись конкретными пользователями, а не гостем. В итоге, в модели осталось 54% последовательностей и 61% событий от всех.
Присутствует возможность посмотреть полную статистику по журналу, по каждой колонке в отдельности (Рис.7).
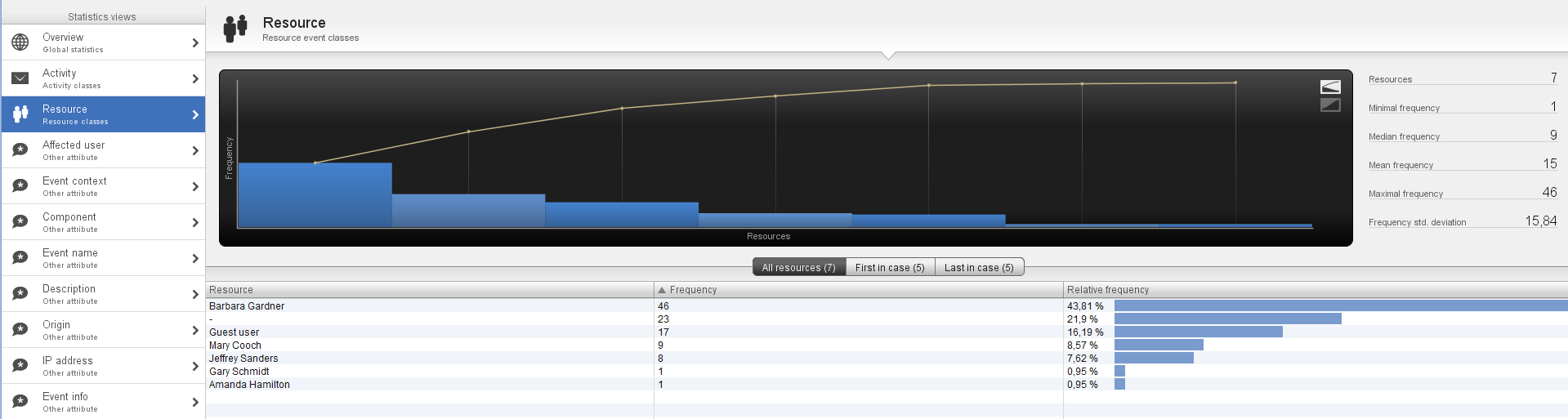
Рис. 7 Показатели статистики по ресурсу
Наблюдается, что примерно 44% всех действия выполнялось пользователем «Barbara Gardner», который выполняет роль студента. На данный момент можно с уверенностью сказать, что пользователей демосайта больше всего интересуют возможности курсов именно для студентов.
Также присутствует инструмент подробного просмотра последовательностей (case). На рисунке 8 показан пример последовательности «прохождения теста» в виде последовательности, а на рисунке 9 в виде таблицы.
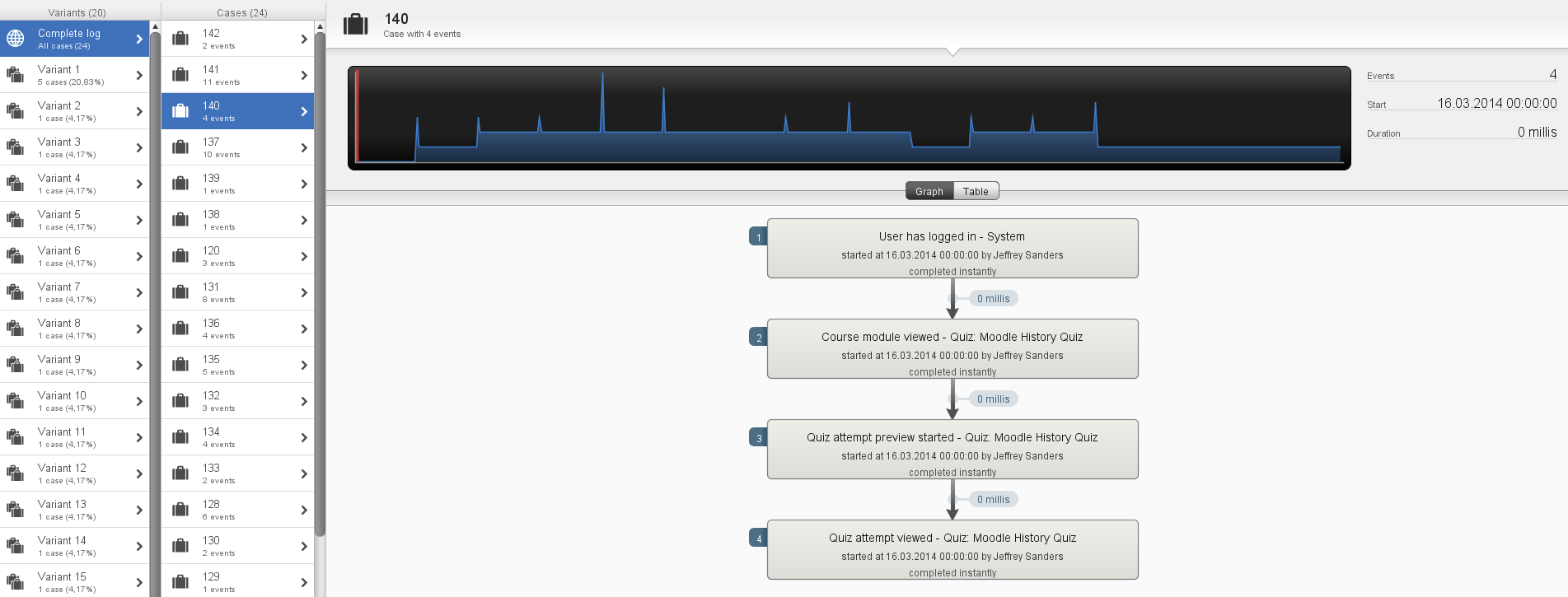
Рис. 8 Пример последовательности.

Рис. 9 Пример последовательности в виде таблицы.
ProM, в отличии от Disco предоставляет более широкие возможности в методах импорта данных. В ProM реализованы практически все основные инструменты Process Mining в виде плагинов, которых насчитывается более 200. Но несмотря на это ProM в основном работает с журналами только в формате MXML и его приемника – XES. XES – XML-подобный формат одобренный IEEE Task Force on Process Mining и описанный в [5].
Для того чтобы его получить есть несколько способов:
-
Сразу выгружать в xes из Disco – не лучший вариант, т.к. когда установлена ограниченная демоверсия мы можем выгрузить только не полный журнал;
-
Через плагин ProM, конвертируя csv в xes – по сути, встроенный XESame в ProM, который может работать только с csv;
-
Через программу XESame, Поставляемую вместе с ProM – самый универсальный и лучший вариант, так как позволяет подключаться к базе напрямую и создавать журнал необходимого вида «без посредников».
В примере рассматривается подключения к тестовой базе mysql, с помощью программы XESame и драйвера jdbc:mysql. Необходимые параметры указываются в поле «URL to databse» в виде «драйвер://host/bdname/?properties». Отмечу, что при работе с версией 6.4. возникли проблемы при подключении к mysql базе из-за внутренних «багов» XESame версий 6.4. и старше, что и отметил разработчик в [6], поэтому использовалась версия 6.3. Данные использовались те же, что и в Disco, с той лишь разницей, что csv файл выгружался в тестовую mysql-базу. Объем данных сохранен для наглядности. Более подробно рассмотреть интерфейс можно в [7].
Далее в атрибутах и параметрах Log’а и Trac’а (он же Case) описываются имя таблицы, или таблиц, откуда берутся данные и другие необходимые параметры. Далее, помимо основных необходимых параметров журнала, можно добавить свои атрибуты, по необходимости. Подробнее этот вопрос разобран в [8]. Стоит отметить, что, из указанных параметров собирается sql запрос, поэтому имена атрибутов в некоторых версиях программы необходимо обрамлять в кавычки.
Далее запускается выгрузка «Execute Conversion» данных в журнал, с необходимыми параметрами.
При импорте журнала в ProM, можно рассмотреть журнал подробнее по тем или иным статистическим показателям (рис. 10), например, в среднем получается по 4 события на последовательность, а классов событий 3.
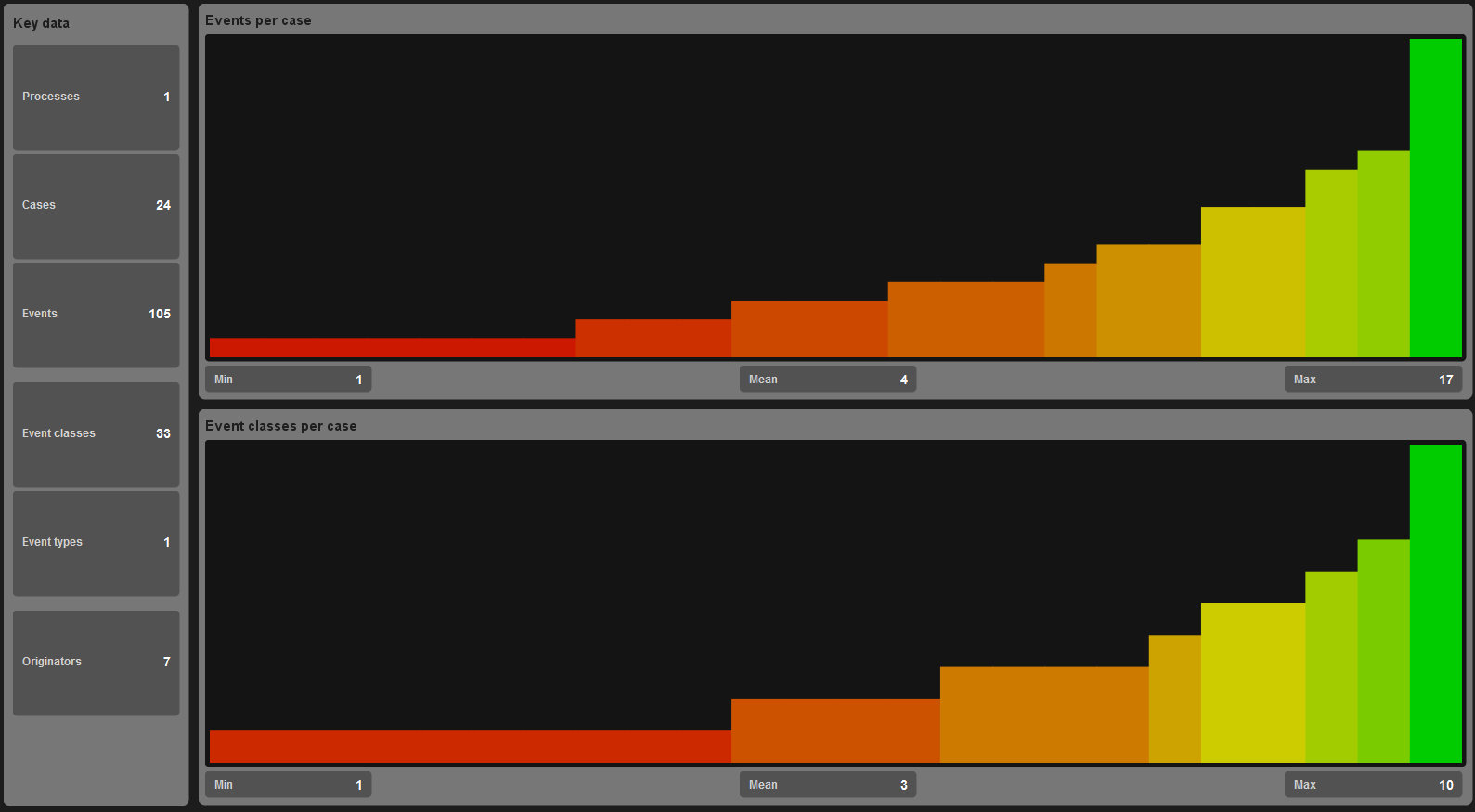
Рис. 10 пример некоторых статистических показателей в ProM
В ProM будет использоваться тот же алгоритм, который представлен в виде плагина в меню «actions» [9] под названием «Mine for a Fuzzy Model». В отличии от Disco, в ProM’е реализована ручная настройка порогов и параметров [4] алгоритма нечеткого поиска.
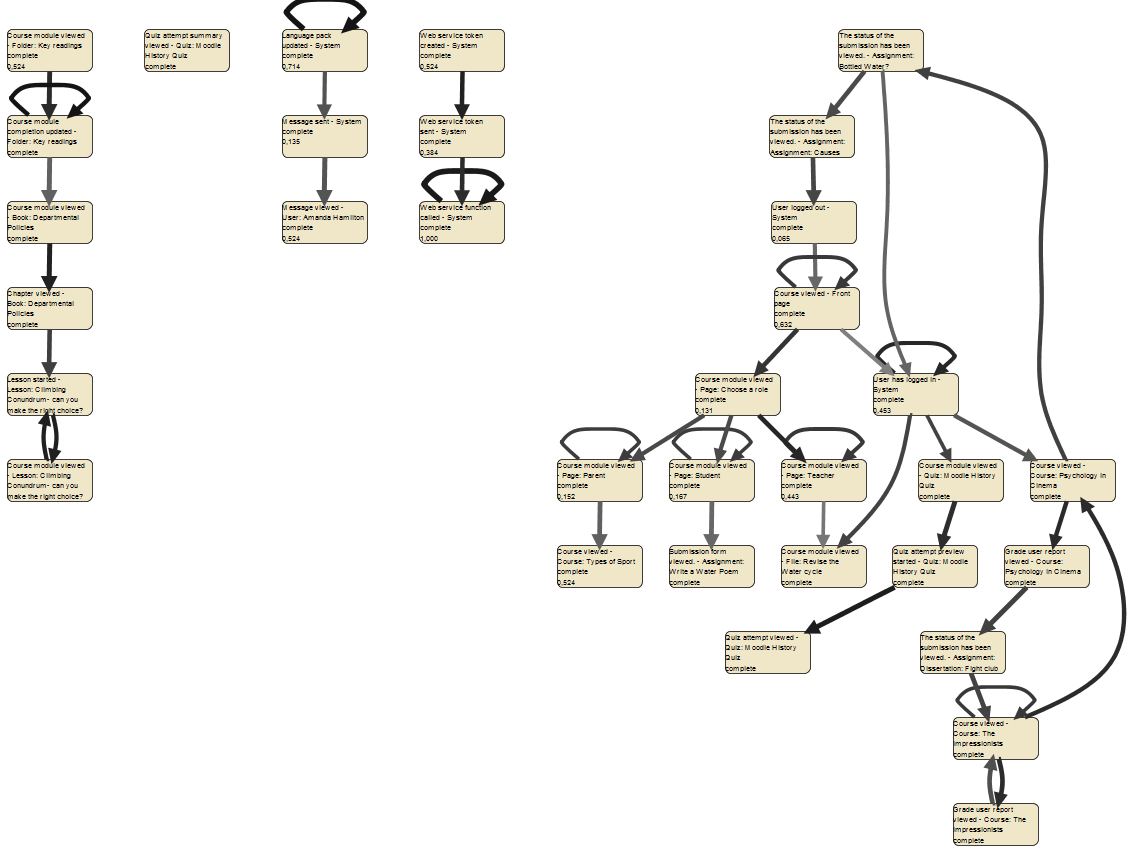
Рис. 11 модель поведения пользователя в ProM
Модель на рисунке 11 получилась практически идентичной модели в Disco на рисунке 3, только лишь с той разницей, что нет псевдо-конечных и начальных событий (их возможно добавить с помощь другого плагина ProM), то есть получились пять отдельных моделей, отображающих основные последовательности действий. Прямоугольники также – действия, дуги – переходы, только в цвете узлов не отображается частота, а в «насыщенности» цвета дуги отображается её показатели полезности [4]. Основное преимущество нечеткой модели в ProM, что она позволяет динамически формировать кластеры действий по ряду параметров. Одним из самых эффективных способов «упрощения» модели считается [4] удаление узлов по показателю значимости. Если установить значение «Signification cuoff» в «Node filter» равный 0,444, то получим модель как на Рис. 12.
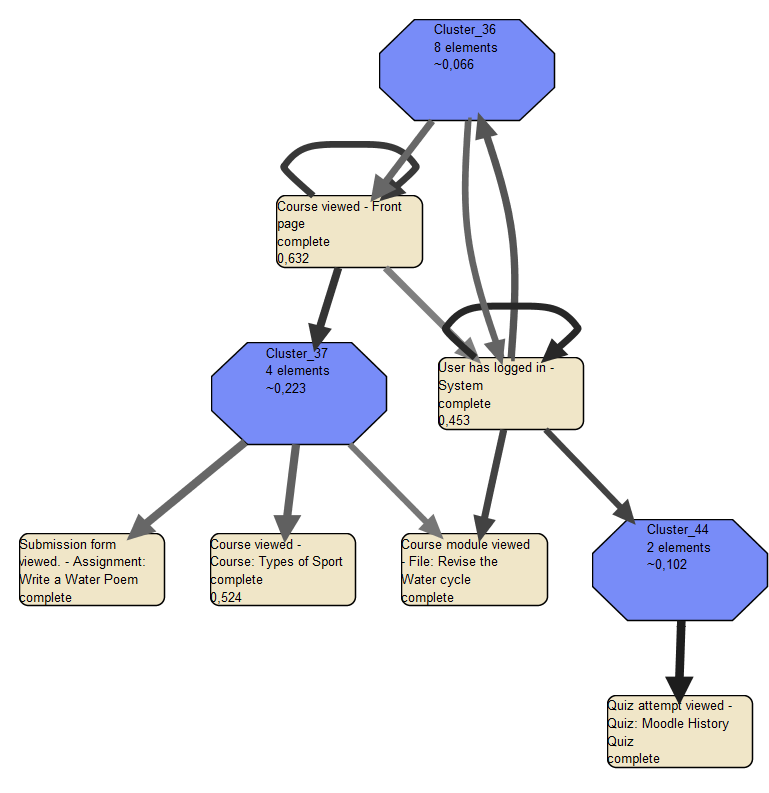
Рис. 12 отфильтрованная модель по значению «Signification cutoff» в «Node filter»
На рисунке 12 оставшиеся 3 маленькие последовательности удалены, так как для анализа ценной информации не несут, кроме как подтверждают необходимость в локализации и работе с курсом и вызовом сервисных функций. Так же можно заметить, что образовались три кластера, которые изображены синими восьмиугольниками в модели. Эти кластеры – совокупность узлов, которых значимость ниже 0.444. То есть на рисунке 12 отображена модель более высокого уровня. Кластеры же можно рассмотреть подробнее двойным нажатием на них в окне ProM (Рис.13). Более светлые узлы и дуги – входящие и исходящие по отношению к кластеру элементы.
Получившиеся кластеры можно назвать как одно действие:
-
кластер 36 – работа с курсом (или просмотр элементов курса)
-
кластер 37 – выбор роли
-
кластер 44 – прохождение теста
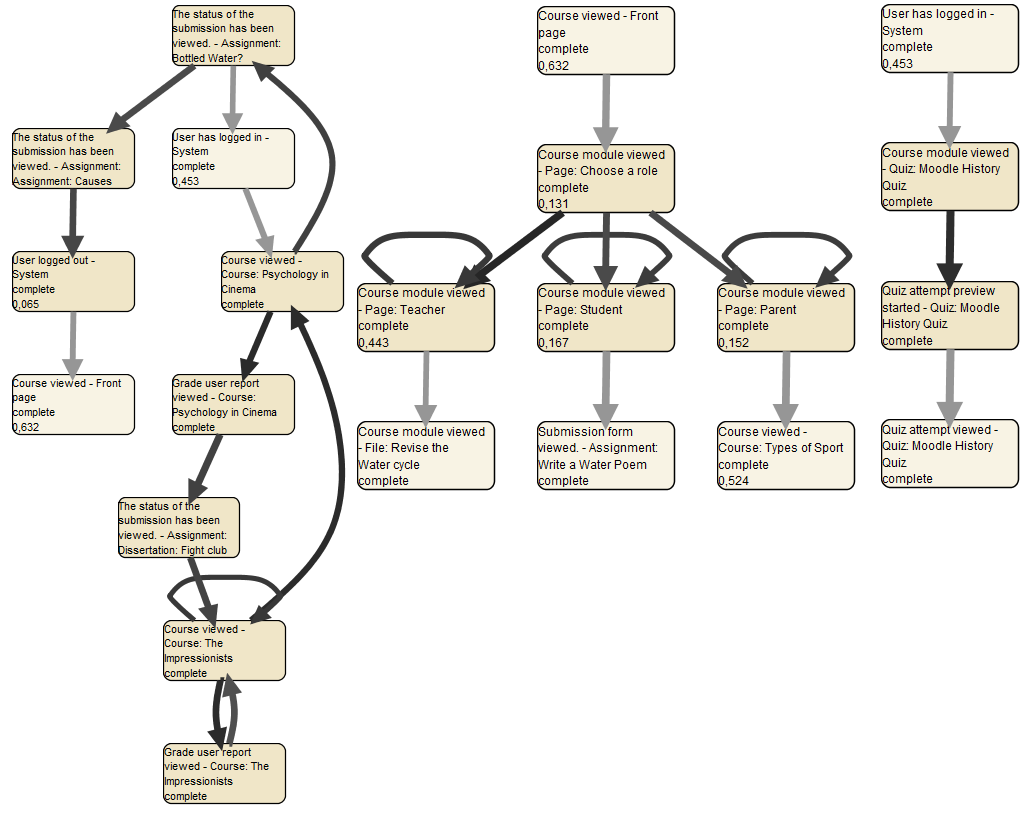
Рис. 13 сластеры (слева-направо) 36, 37, 44
Однако у алгоритма нечеткого поиска всетаки тоже есть недостатки [10] , которые проявляются при работе в ProM:
-
Большие затраты времени: границы каждого порога варьируются от 0 до 1, и таких порогов несколько [4], тем самым порождая тысячи вариантов модели;
-
Алгоритму не хватает комплексной оценки качества полученной модели
Для решения этих проблем есть плагин «Select Best Fuzzy Instans», задача которого вывести лучший вариант последовательностей из готовой модели процессов. Но результат его работы не всегда координально отличается от первоначальной модели , например, на рис. 14 представлен результат работы этого плагина, он практически идентичен первоначальной модели (Рис. 11).
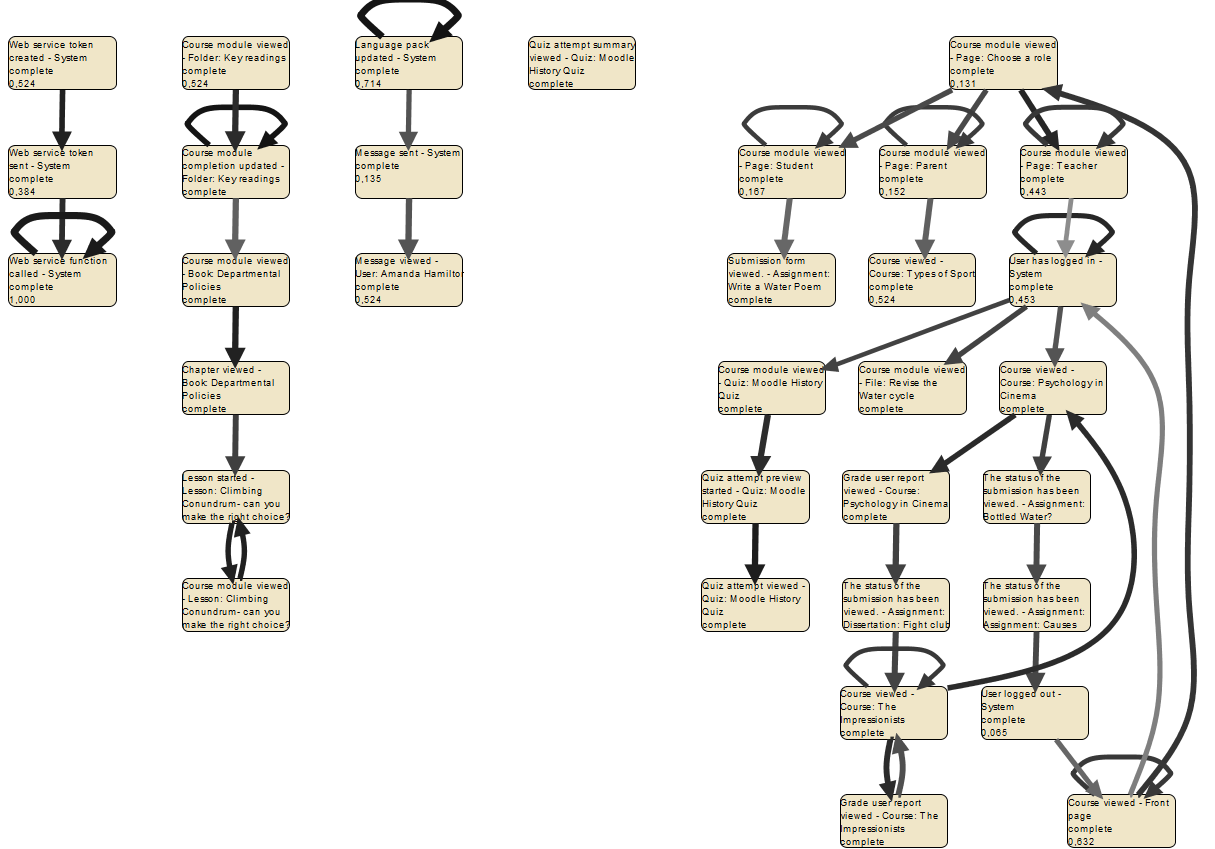
Рис. 14 результат работы плагина «Select Best Fuzzy Instans»
В примере можно убедиться, что Disco удобнее в использовании для анализа журналов событий, но ограничен не только в выборе алгоритмов анализа, но и лицензией. ProM показал же себя достаточно мощным инструментом, из недостатоков которого можно отметить нестабильность в работе.
Таким образом, были получены модели поведения пользователей на демосайте, и исходя из этих моделей сделаны выводы, что пользователи, посетившие демосайт в выбранный день были заинтересованы в локализации ресурса, ознакомлении с возможностями курсов для студентов, ролевой модели ресурса.
Пример показывает, что методы анализа событий применимы не только в корпоративной среде.
Библиографический список
-
Wil M.P. van der Aalst, Process Mining. Discovery, Conformance and Enhancement of Business Processes, Springer-Verlag Berlin Heidelberg 2011
- Process Mining Manifesto [Электронный ресурс]. URL: http://www.win.tue.nl/ieeetfpm/lib/exe/fetch.php?media=shared:process_mining_manifesto-small.pdf (дата обращения: 20.05.2015)
-
ProM Tips — Which Mining Algorithm Should You Use? Anne, 18 Oct. [Электронный ресурс]. URL: https://fluxicon.com/blog/2010/10/prom-tips-mining-algorithm/ (дата обращения: 20.05.2015)
-
Christian W. Günther and Wil M.P. van der Aalst. Fuzzy Mining – Adaptive Process Simplification Based on Multi-Perspective Metrics, 2007
-
XES Standart. [Электронный ресурс]. URL: http://www.xes-standard.org/ (дата обращения: 20.05.2015)
-
ProM forum. [Электронный ресурс]. URL: http://www.win.tue.nl/promforum/discussion/445/how-to-specify-db-table-in-xesame-connection/p1 (дата обращения: 20.05.2015)
- XESame user interface. [Электронный ресурс]. URL: http://www.promtools.org/doku.php?id=gettingstarted:xesameui (дата обращения: 20.05.2015)
-
J.C.A.M. Buijs. Mapping Data Sources to XES in a Generic Way. Eindhoven, March 2010
- XESame user interface. [Электронный ресурс]. URL: http://www.promtools.org/doku.php?id=gettingstarted:prom6ui (дата обращения: 20.05.2015)
-
Jiaojiao Xia. Automatic Determination of Graph Simplification Parameter Values for Fuzzy Miner. Eindhoven, October 2010, стр. 29
Количество просмотров публикации: Please wait