

Введение
Речевое взаимодействие для человека является привычным, позволяет увеличить скорость взаимодействия с ЭВМ. Распознавание речи может трактоваться как преобразование речи диктора в текст, распознавание команды с последующим её выполнением, выделение из речи каких-либо параметров – все это в разных источниках может попасть под это определение.
Несмотря на достаточный прогресс в данном направлении исследований, автоматическое распознавание речи продолжает оставаться достаточно сложной задачей. Это объясняется рядом характерных особенностей речевого сигнала, которые значительно затрудняют решение этих задач.
Все известные методы распознавания речи не позволяют определить конкретный вид анализа и параметры речевого сигнала, которые могут дать наилучший результат. Поэтому, разработка алгоритмов работы для систем распознавания речи сводятся к анализу уже существующих систем. Также производится поочередное рассмотрение методов параметризации сигнала и экспериментальное исследованию их эффективности.
Постановка задачи
Целью работы является нахождение эффективного алгоритма для распознавания команды из потока входного звукового сигнала, которая заранее определена набором команд; выполнение практической реализации алгоритма.
Для достижения цели необходимо произвести выделение из исходного речевого сигнала информативных характеристик, которые полноценно описывают исходный сигнал, но требуют меньших вычислительных затрат при обработке. Далее производится сравнение массивов информативных признаков анализируемой команды и образца произношения. На основании произведенного анализа, выбирается текстовое представление наиболее схожего образца и выводится пользователю.
Вычисление мел-частотных кепстральных коэффициентов (MFCC)
Коэффициенты MFCC хорошо зарекомендовали себя в задачах распознавания речи. По сравнению с альтернативными методами выделения признаков из речевого сигнала (LPC, PLP), результаты распознавания были лучше [1].
На рисунке 1 представлен процесс вычисления MFCC [2]. На первом шаге вычисляются компоненты спектра Фурье. Далее спектр сглаживается при помощи операции свертки с треугольными окнами.
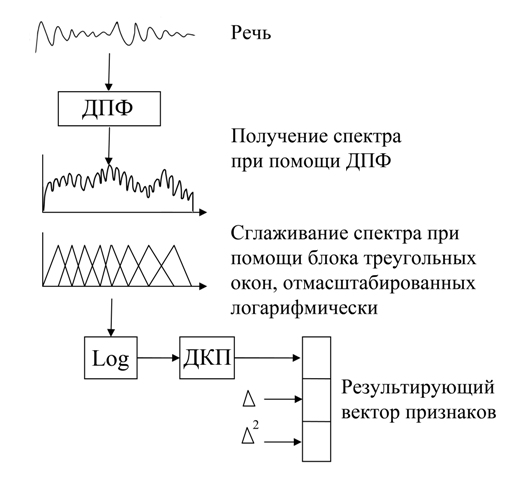
Рисунок 1 – Процесс вычисления кепстральных коэффициентов
Формально операция сглаживания определяется следующим образом:
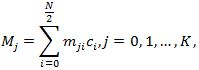
где c i , i=0, …, N/2 – спектр сигнала;
К – количество окон;
mij – величина j-ой оконной функции.
Оконная функция выражается через величины aj – начало j-ого треугольного окна следующим образом:
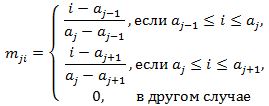
Окончательно MFCC коэффициенты получаются при помощи дискретного косинус-преобразования:
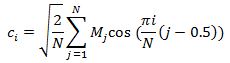
MFCC преобразование по сути является сжатием спектральных данных, что значительно упрощает дальнейшее сравнение распознаваемой команды с набором эталонных команд за счет уменьшения размерности вектора признаков.
В качестве итоговых значений берутся первые несколько коэффициентов дискретного косинусного преобразования.
Классический метод динамического трансформирования времени (DTW)
DTW относится к методам динамического программирования. Он используется для сравнения распознаваемого сигнала с эталонами и учитывает динамические изменения во времени [3].
Метод динамического трансформирования времени вычисляет оптимальную последовательность трансформации времени для двух временных рядов.
Пусть дано два временных ряда Q и C длиной соответственно n и m:
Q=q1,q2,…,qn, C=c1,c2,…,cm
По этим последовательностям строится путь наименьшей стоимости.
Определим матрицу Ωn∙m так, чтобы её элемент соответствовал расстоянию между i-ым и j-ым элементами последовательностей Q и C, т.е. соответствовал выравниванию между qi и cj. Возьмем евклидово расстояние:
![]()
По матрице Ω построим путь W. Этот путь показывает соответствие между Q и C. k-ый элемент W определяется как wk = (i, j). Путь W имеет следующий вид:
W=w1,w2,…,wk,…,wK,
где К – длина пути.
К удовлетворяет следующему условию:
min(m,n)≤K<m+n-1
Путь W должен удовлетворять следующим ограничениям:
1. Граничные условия
Обычно допускают, что w1 = (1, 1) и wK = (n, m). Таким образом начало и конец W находятся на диагонали в противоположных углах Ω.
2. Непрерывность
Обход последовательности происходит постепенно – за один шаг индексы i-ый и j-ый увеличиваются не больше, чем на единицу. Пусть wk = (a,b) и wk-1 = (p,q), тогда:
a-p≤1, b-q≤1
Данное ограничение необходимо, чтобы в шаге пути W брали участие только соседние элементы матрицы.
3. Монотонность
Пусть wk = (a,b) и wk-1 = (p,q), тога
a-p≥0, b-q≥0
Это ограничение необходимо, чтобы точки W монотонно перемещались во времени.
Путей, которые удовлетворяют этим трем условиям, может быть очень много. Поэтому необходимо выбрать путь, на котором достигается минимум стоимости пути:
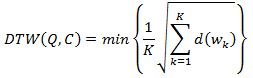
Знаменатель К необходим, чтобы учесть разную длину W.
Таким образом, путь наименьшей стоимости (выравнивающий путь) для последовательностей Q и C – это путь W, на котором достигается минимум стоимости пути DTW(Q,C).
Классический алгоритм поиска пути с минимальной стоимостью рекурсивно находит длину пути наименьшей стоимости γi,j для каждого элемента матрицы Ω:
![]()
Сравнение входного образа с набором эталонов
Задачей распознавания образов является сопоставление входного образа с определенным существующим классом (моделью команды). Цель распознавания – оценить модель команды, к которой входные данные принадлежат с большей вероятностью [4].
Задание системы распознавания речи состоит в том, чтобы по речевому сигналу правильно идентифицировать сказанную диктором команду. Это соответствует оптимальному критерию, который может быть выражен:
![]()
где ![]() – выходная гипотеза фразы;
– выходная гипотеза фразы;
w – произнесенная последовательность слов;
W – набор всех возможных последовательностей слов;
O – последовательность векторов признаков, вычисленных по входному речевому сигналу.
Экспериментальные исследования
Для обучения системы распознавания речи использовались 10 команд, надиктованные четырьмя дикторами (3 мужских голоса и 1 женский).
Для тестирования было сформировано 2 теста. Каждый тест состоит из полного набора команд, который озвучило 2 диктора с мужским голосом, причем голосом одного был записан также обучающий набор.
Обучение производилось по очереди на голосе каждого диктора по отдельности, а потом – с использованием всех голосов. После каждого из пяти обучений производилось тестирование.
При обучении на голосе только одного диктора средняя вероятность распознавания составила 46%, зависимости качества распознавания от голоса диктора не наблюдалось. При обучении на голосах одновременно всех дикторов вероятность распознавания повысилась до 70%.
Выводы
В работе рассмотрена структура системы распознавания речи. Описана комбинация метода получения информативных признаков речевого сигнала (MFCC) с методом сравнения последовательностей векторов признаков. Метод сравнения (DTW) позволяет учитывать различную скорость произнесения команды. Также описан критерий оптимальности, который позволяет выбрать модель команды, соответствующую входному сигналу. Проведены экспериментальные исследования.
Библиографический список
- Performance Analysis of LPC, PLP and MFCC Parameters In Speech Recognition / Mahesh Goyani, Namrata Dave // National Conference on Advance Computing. – P. 174-178.
- Аграновский А.В Теоретические аспекты алгоритмов обработки и классификации речевых сигналов / А.В. Аграновский, Д.А. Леднов. Москва: Изд-во «Радио и связь», 2004. – 164с.
- Винцюк Т.К. Анализ, распознавание и интерпретация речевых сигналов. – Киев: Наукова думка. – 1987. – 264 с.
- Кипяткова И.С. Автоматическая обработка разговорной русской речи: монография / И.С. Кипяткова, А.Л. Рожнин, А.А. Карпов. СПИИРАН. – СПб.: ГУАП, 2013. – 314с.
Количество просмотров публикации: Please wait